目前开源的激光雷达SLAM学习。
概述
激光雷达SLAM
SLAM问题被认为是真正意义上实现机器人自主移动的关键。其问题可以理解为如下的生活问题。
当你来到一个陌生的环境时,为了迅速熟悉环境并完成自己的任务(比如找饭馆,找旅馆),你应当做以下事情:
a. 用眼睛观察周围地标如建筑、大树、花坛等,并记住他们的特征(特征提取)
b. 在自己的脑海中,根据双目获得的信息,把特征地标在三维地图中重建出来(三维重建)
c. 当自己在行走时,不断获取新的特征地标,并且校正自己头脑中的地图模型(bundle adjustment or EKF)
d. 根据自己前一段时间行走获得的特征地标,确定自己的位置(trajectory)
e. 当无意中走了很长一段路的时候,和脑海中的以往地标进行匹配,看一看是否走回了原路(loop-closure detection)。实际这一步可有可无。
以上五步是同时进行的,因此是simultaneous localization and mapping。
SLAM算法在实现的时候主要要考虑以下4个方面吧:
-
地图表示问题,比如dense和sparse都是它的不同表达方式,这个需要根据实际场景需求去抉择
-
信息感知问题,需要考虑如何全面的感知这个环境,RGBD摄像头FOV通常比较小,但激光雷达比较大
-
数据关联问题,不同的sensor的数据类型、时间戳、坐标系表达方式各有不同,需要统一处理
-
定位与构图问题,就是指怎么实现位姿估计和建模,这里面涉及到很多数学问题,物理模型建立,状态估计和优化
其他的还有回环检测问题,探索问题(exploration),以及绑架问题(kidnapping)。
本文主要学习激光雷达SLAM,激光雷达传感器利用光原理进行工作,激光雷达代表光探测和测距。它们可以探测到300米以内的障碍物,并准确估计它们的位置。在自动驾驶汽车中,这是用于位置估计的最精确的传感器。
激光雷达传感器由两部分组成:激光发射(顶部)和激光接收(底部)。发射系统的工作原理是利用多层激光束,层数越多,激光雷达就越精确。层数越多,传感器就越大。激光被发射到障碍物并反射,当这些激光击中障碍物时,它们会产生一组点云,传感器与飞行时间(TOF)进行工作,从本质上说,它测量的是每束激光反射回来所需的时间。
当激光雷达的质量和价格非常高时,激光雷达是可以创建丰富的三维环境,并且每秒最多可以发射200万个点。点云表示三维世界激光雷达传感器获得每个撞击点的精确(X,Y,Z)位置。
激光雷达传感器可以是固态的,也可以是旋转的,固态激光雷达将把检测的重点放在一个位置上,并提供一个覆盖范围(比如FOV为90° )。在后一种情况下,它将围绕自身旋转,并提供360度旋转。在这种情况下,一般把它放在设备顶上,以提高能见度。
激光雷达很少用作独立传感器。它们通常与相机或雷达结合在一起,这一过程称为传感器融合。融合过程可分为早期融合和后期融合。早期融合是指点云与图像像素融合,后期融合是指单个检测物的融合。
激光雷达进行障碍物的步骤通常分为4个步骤:
-
点云处理
-
点云分割
-
障碍聚类
-
边界框拟合
为了处理点云,我们可以使用最流行的库PCL(point cloud library)。它在Python中可用,但是在C++中使用它更为合理,因为语言更适合机器人学。它也符合ROS(机器人操作系统)。PCL库可以完成探测障碍物所需的大部分计算,从加载点到执行算法。这个库相当于OpenCV的计算机视觉。因为激光雷达的输出很容易达到每秒100000个点,所以我们需要使用一种称为体素网格的方法来对点云进行下采样。体素网格是一个三维立方体,通过每个立方体只留下一个点来过滤点云。立方体越大,点云的最终分辨率越低。最终,我们可以将点云的采样从几万点减少到几千点。
滤波完成后我们可以进行的第二个操作是ROI(感兴趣区域)的提取,我们只需删除不属于特定区域的每一些点云数据,例如左右距离10米以上的点云,前后超过100米的点云都通过滤波器滤除。现在我们有了降采样并滤波后的点云了,此时可以继续进行点云的分割、聚类和边界框实现。
点云分割任务是将场景与其中的障碍物分离开来,其实就是地面的分割。一种非常流行的分割方法称为RANSAC(RANdom Sample consenses)。该算法的目标是识别一组点中的异常值。点云的输出通常表示一些形状。有些形状表示障碍物,有些只是表示地面上的反射。RANSAC的目标是识别这些点,并通过拟合平面或直线将它们与其他点分开。
可以考虑线性回归。但是有这么多的异常值,线性回归会试图平均结果,而得出错误的拟合结果,与线性回归相反,这里的ransac算法将识别这些异常值,且不会拟合它们。
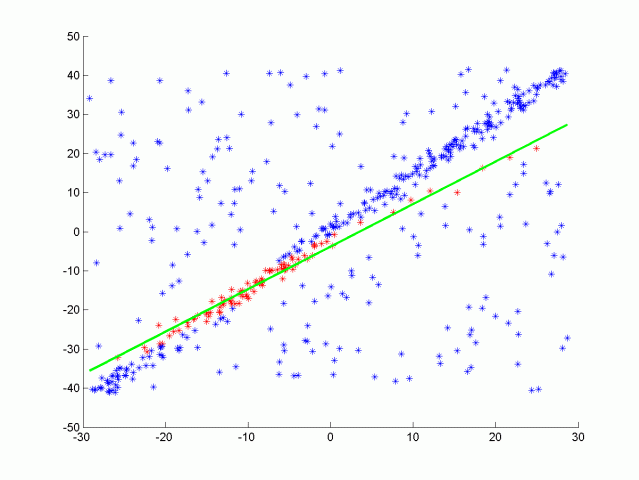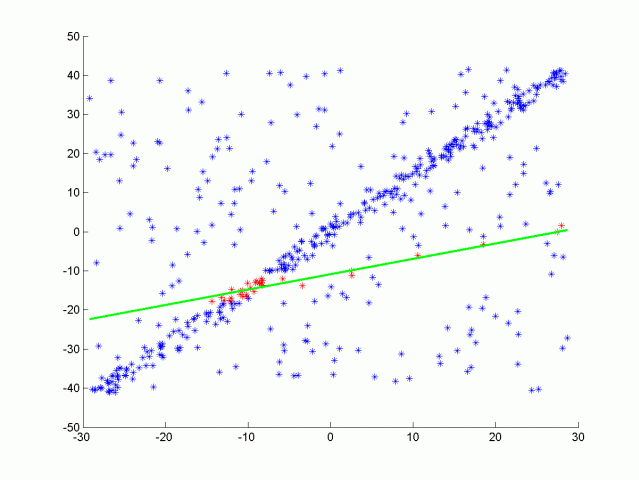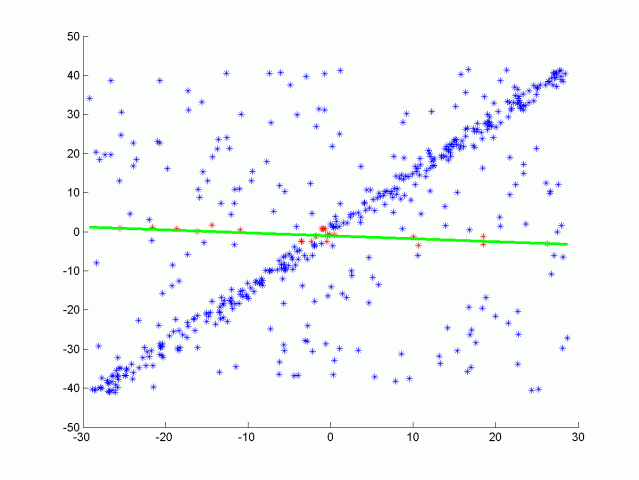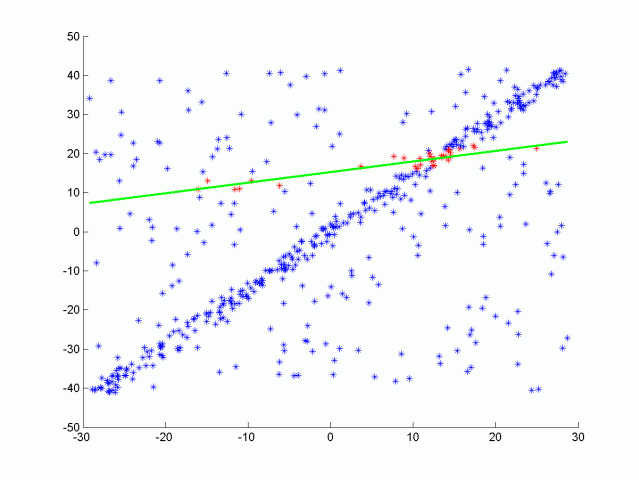
如上图所示我们可以将这条线视为场景的目标路径(即道路),而孤立点则是障碍物。它是如何工作的?
过程如下:
-
随机选取2个点
-
将线性模型拟合到这些点计算每隔一点到拟合线的距离。如果距离在定义的阈值距离公差范围内,则将该点添加到内联线列表中。
因此需要算法一个参数:距离阈值。
- 最后选择内点最多的迭代作为模型;其余的都是离群值。这样,我们就可以把每一个内点视为道路的一部分,把每一个外点视为障碍的一部分。RANSAC应用在3D点云中。在这种情况下,3个点之间的构成的平面是算法的基础。然后计算点到平面的距离。
RANSAC是一个非常强大和简单的点云分割算法。它试图找到属于同一形状的点云和不属于同一形状的点云,然后将其分开。
激光雷达从2D到3D(Cartographer)
Cartographer是由谷歌于2016年开源的一个支持ROS的室内SLAM库,并在截至目前为止,仍然处于不断的更新维护之中。 特点:代码极为工程,多态、继承、层层封装的十分完善。提供了方便的接口,便于接入IMU、(单/多线)雷达、里程计、甚至为二维码辅助等视觉识别方式也预留了接口(Landmark)。
-
2D-SLAM:基于2D栅格地图,可以直接用于导航。
-
3D-SLAM:基于hybridGrid,译为混合概率地图,可以理解为3D栅格地图。 明确:RViz 仅显示3D混合概率网格的2D 投影(以灰度形式)。该地图难以直接使用。
在Cartographer前端中,不断维护的是scan和submap之间的位姿。整个的map是由一个个submap组成的。
Cartographer的匹配方法
Cartographer采用的是scan-map的匹配方法。 一般情况的SLAM有如下三种:
- scan-scan: 这个意味着利用两帧激光数据(每帧激光束的数目相同),计算二者之间的变换。典型方法:ICP。
- scan-map: 利用一帧激光数据和地图数据,找到激光数据在地图中的位置。
- map-map: 利用一个子地图数据,在一个更大的地图中找到它合适的位置。
不管是2D还是3D,首先要有一个初始的位姿,在此基础上进行优化:
- 有IMU,则采纳其角速度积分作为初始姿态。不信任IMU任何加速度信息。
- 有里程计,则采纳里程计的线速度积分作为初始平移。
- 二者都没有,根据之前的运动做一个匀速的假设。
注意,cartographer的多传感器融合是一个松耦合,主要依赖激光来定位。IMU和里程计数据并没有被构建到真正优化的目标函数中。
在得到了初始位姿以后,初始位姿要经过第一阶段解算:CSM(Correlation Scan Match 相关扫描匹配)——构建似然场。即对原先的地图map进行一个高斯模糊,让它膨胀一些,然后把激光scan在一个搜索窗口内暴力匹配,计算得分。注意,这里有两个问题:
1.得分怎么算?
- 如果scan的点落在障碍物模糊区域内,落的越多,得分越高。
2.地图不是无限大的吗,你怎么保证在搜索窗口里就能找到位姿呢?
- 因为有初始位姿。误差肯定在一个范围内而不会马上发散到很远,所以可以在一个位姿的窗口内,对位姿进行暴力匹配搜索。(初始位姿估计中,里程计数据不会突然激增;imu的加速度信息会漂移,但是算法对于imu加速度数据选择直接丢弃不看;而根据之前位姿匀速假设也不会飘走)
这时候我们就要考虑,什么是位姿?位置+姿态。对于2Dslam而言,有三个变量,$x$,$y$,$yaw$角。 对于3Dslam而言,有$x$,$y$,$z$,$roll$,$pitch$,$yaw$六个变量。
- 2dslam中,采用三层循环,(最外层为θ,减小sin和cos的频繁计算),对$x$,$y$,$\theta$在给定大小的搜索窗口内进行穷举,计算最高得分的$x$,$y$,$\theta$作为一阶段解算的输出位姿。
- 3dslam中,采用六层循环,对$x$,$y$,$z$,$roll$,$pitch$,$yaw$六个变量在搜索窗口内穷举,计算得分最高的作为一阶段解算输出位姿。 很显然,3d-slam的这种方式对于计算资源依赖较大,复杂度达到$O(n^6)$级别。因此3d-slam的CSM方法,作为一个配置选项,默认是不开启的。当然如果用户机器比较牛逼,也可以选择开启。
第一阶段CSM解算中,位姿在其中是一个离散的变量,通过暴力枚举获得输出结果;但是暴力枚举也是存在分辨率的,例如:如果角度步长设为$1$度,但如果刚好真正的角度是$5.5$度,那么CSM只能搜索到$5$或$6$度,而无法进一步细化,逐步累积将会造成误差。 因此,引入第二阶段位姿解算:非线性优化。
\[E(T)=\arg \min _{T} \sum\left[1-M\left(S_{i}(T)\right)\right]^{2}\]$S_i(T)$表示把激光数据$S$用位姿$T$进行转换,$M(x)$表示得到坐标$x$的地图占用概率。思路:$S$代表了激光击中障碍物,将激光点在机器人坐标系下的位置,经过$T$转换到世界坐标系下以后,应该尽可能的落在已有地图的障碍物上。
第二阶段的位姿求解,显然位姿在其中是一个连续的变量,通过梯度下降的方法求解目标函数。由于地图是离散的,因此需要对地图进行插值处理,使地图也变成一个可以求导的连续变量,这样才能优化前述目标函数。
线性插值:已知数据 $(x_0, y_0)$ 与$ (x_1, y_1)$,要计算 $[x_0, x_1]$ 区间内某一位置 $x$ 在直线上的$y$值;
双线性插值本质上就是在两个方向上做线性插值。 双三次插值:更加复杂的插值方式,它能创造出比双线性插值更平滑的图像边缘。使用最近$16$个点插值。
Cartographer的建图方法
Cartographer的地图(map)以子地图(submap)的形式组成。分为前端和后端。 前端:根据帧间匹配算法(scan-match),实时根据激光(scan)来推测累积的scan相对于submap的位姿。 后端:检测回环(发现在已到达的位置附近),修正各个submap之间的位姿。根据代码可以判断,2D和3D基于的是同一套思路,但是在实现上有一定区别。 接下来结合2D和3D部分,对比介绍实现定位和建图的方法。
Cartographer的后端
Cartographer在后端主要寻找回环,并根据建立的约束对所有的sumap进行统一优化。 回环检测目的是:检测当前位置是否曾经来过,即采用当前scan在历史中搜索,确认是否匹配。
为什么要有回环检测呢?原因有二:
- 已有地图时位姿初始化,不知道当前帧初始位姿,也就不清楚在地图中哪个位置,无法做定位。
- 有累积误差,仅靠前端递推,不进行修正的话,地图很容易变形。
因此接下来我们探讨两个问题:1. 如何检测回环。2. 检测回环后该怎么做。
如何检测回环
检测回环和前端的思路也比较相似,先通过穷举暴力匹配,再通过优化精细修正。但是,前端的暴力穷举,是在有个初始位姿的基础上在一个小窗口内穷举。 后端重定位,没有初始位姿了,暴力匹配的范围变成了整个地图。 因此必须采用算法加速处理:多分辨率地图+分枝定界操作。
假设有一帧激光:

蓝色代表障碍物:

在高分辨率的地图上,四个点命中3个;在低分辨率的地图上,四个点全部命中。激光在低分辨率的地图上匹配情况: 代表得分的上界 (再往精细展开,匹配得分只能更低,不能更高) 在高分辨率的地图上匹配情况: 代表得分的下界( 再往粗略缩放,匹配得分只能更高,不会更低)
分支定界:
- 先把整个地图中的一个区域展开到底(最高分辨率),得到一个匹配分数(得分下界);
- 然后把其他区域不展开,算匹配分数。(得分上界)
- 如果低分辨率区域的得分上界,还没有已展开到底的高分辨率区域的下界高,这个低分辨率区域就不再展开了,统统丢掉不要。
左图四个命中$3$个,得分$75$; 右图四个命中$2$个,得分$50$; 那么激光打在子区域A的可能性就要大于B,因此B就无需继续展开成更精细的地图了。
- 2D-slam的思路比较简单 前端:小范围内穷举+非线性优化方法修正位姿。 回环检测:大范围内穷举(利用分支定界加速) +非线性优化修正位姿。
- 3D-slam有所不同。 前端的暴力匹配方法,是直接6层循环暴力枚举的,因此配置文件中默认不开启,而是在初始通过IMU、里程计等预测位姿基础上,直接非线性优化修正位姿。 如果回环检测仍然是:大范围内6个循环穷举+分支定界的话,小范围都嫌慢,大范围更别提。 直接对位姿非线性优化? 1.没有初值,会算到猴年马月。2.会落入局部最优值。
回环检测后,就到优化了~而优化的本质,还是一个最小二乘问题。
LOAM (Lidar Odometry and Mapping in Real-time)
LOAM是Ji Zhang早期开源的多线LiDAR SLAM算法。该代码可读性很差,作者后来将其闭源。其效果如下:

上文介绍的cartographer主要解决室内问题,LOAM室内外都可以,但是没有回环检测。Cartographer的3D部分,更像是2D的扩展:即用2D的思路去做3D的事情。而LOAM则主要解决3D问题,其核心思路难以解决2D问题。虽然该算法发表于14年RSS,但是在KITTI上的Odometry模块(The KITTI Vision Benchmark Suite)的激光SLAM排行榜上,仍然霸占前列。
由于LOAM的工程已经闭源。本文在此处采用下面两个github工程来查看LOAM的效果~
其框架如下图所示

- Point Cloud Registration:点云不是同一时刻获取的,每一个帧点云,其中的每一个点,都是不同时刻获取的,因此把它进行运动补偿: 获取每个点的时间戳,位姿插值,把点云先投影到同一时刻;提取特征点。
- Lidar Odometry: 估计两帧点云之间的位姿变换,获得两个时刻之间的相对位姿,频率较高 10Hz
- Lidar Mapping: 建图模块,把连续10帧的点云数据和整个地图匹配,获得世界坐标系下的位姿,频率较低 1Hz。
- Transform Intergration:实时利用世界坐标系下的位姿和两个时刻之间的相对位姿,更新各个时刻世界坐标系下的位姿。
Cartographer使用栅格地图,地图中存储着占据概率,通过把点云投影到栅格地图,计算匹配得分,找到最合适的投影,作为位姿变换。但是,LOAM使用的是点云地图,那么点云投影后,进行匹配的就还是点云地图。 两堆点云,如何匹配?
传统方法,使用ICP方法,即默认两堆点云中最近的点是匹配点,构建矩阵进行奇异值分解,得到变换矩阵后投影点云,然后再次寻找匹配点,重新计算投影……直至收敛。然而,对SLAM算法而言,要求同步定位和建图。这样随便根据距离选匹配点,计算太复杂,可能算来算去都不收敛,压根就不能实时,计算量实在是太大了。LOAM作者决定对点云提取特征,然后根据稀疏的特征来计算位姿变换。 作者决定提取两种特征点:平面点和边缘点。
对于平面点与边缘点,作者引入曲率计算方法
计算曲率听起来是一个很麻烦的事情,在高等数学中,一条曲线的曲率以如下公式进行计算:
\[K=\frac{\left|y^{\prime \prime}\right|}{\left(1+y^{\prime 2}\right)^{\frac{3}{2}}}\]但事实上作者并不是这样算的。他直接利用激光的每条扫瞄线中,一个点前后各五个点,计算平均值到该点的距离。
\[c=\frac{1}{|S| \cdot\left\|\mathbf{X}_{(k, i)}^{L}\right\|} \sum_{j \in S, j \neq i}\left\|\mathbf{X}_{(k, i)}^{L}-\mathbf{X}_{(k, j)}^{L}\right\|\]