嵌入式AI TinyML边缘智能学习汇总笔记。
1 前言
最近几年,无论是学术界,还是工业界比如Nxp、ST、瑞萨的官网,还有IAR IDE厂商,都为嵌入式AI进行了铺垫,我曾经看过一个Nxp的应用案例,将AI应用到电机的故障诊断分析检测效果极其好,所以不免感慨,也许这方面的确是不小的机会,加上以往的自己学习过寒武纪的智能计算系统的AI算法移植,现在又在芯片原厂,对MCU的底层算是比较熟悉,加上以往追了一段时间MIT韩松的论文,觉得这是本人一个不错的机会,这里博客上是搬运的台湾小哥的文章。
2 认识神经元、神经网络及卷积神经网络
从[1]文中可知,目前tinyML最主要应用为智能传感器,如声音(麦克风)、环境(温度、湿度、气压、照度)、运动(加速度、陀螺仪、地磁计)等。 而视觉部份(影像感测器)则由于对算力(含时钟速度)、代码空间(Flash)及随机记忆体(SRAM)需求较高,所以仅适用在较高阶MCU,主要应用则落在较小尺寸影像分类及物件侦测,而影像分割或姿态估测等就较少出现在tinyML应用上。
在说明MCU和NPU如何帮助tinyML前,这里还是得简单说明一下深度学习技术发展脉络及基础原理,以便大家更容昜理解如何实现MCU等级的AI应用及为何要使用神经网络处理器(Neural network Processing Unit, NPU) 。
2012年Alex Krizhevsky使用 卷积神经网络(Convolutional Neural Network, CNN) 狂胜ImageNet影像辨识大赛后,正式开启了人工智能(Artificial Intelligence, AI) 及 深度学习(Deep Learning, DL) 风潮。 而其中最重要的核心元素就是神经元、神经网络及卷积神经网络。 这里就直接借用去(2021)年小弟曾写过的系列文章「iThome 2021 (13届) 铁人赛【arm platforms组】完赛记录 ─ 争什么,把AI和MCU掺在一起做tinyML就对了! 」[2]中的「[Day 04]深度学习与神经网络」, 「[Day 05]tinyML与卷积神经网络(CNN)」来说明。
如Fig. 1左侧所示,为基本神经元结构,假设有三个输入值X1到X3和三个权重值(Weight)W1到W3,神经元会将所有输入乘以各自权重值后加总,再加上一个偏置量(Bias),最后再配合一个激励函式(Activation Function)得到输出值。 而如Fig. 1右侧所示,即为最简单的全链接(Full Connected)神经网络架构,主要可分为输入层、隐藏层和输出层,有时也会把神经网络称为「模型」。 其中隐藏层层数及各层的神经元数量皆可自由调整。 当隐藏层层数大于一时又可称为 深度神经网络(Deep Neural Network, DNN) 。 从这里已经可以看到需要大量的 乘积累加运算(Multiply Accumulate, MAC) 才能完成输出值计算。 而这样的结构通常只适用少量输入值及少量输出值的应用,刚好符合智能传感器应用的需求。

Fig. 1 神经元及神经网络基本架构图[2]。 (OmniXRI整理理绘制,2021/9/17)
接下来就以小型影像分类最知名的CNN模型LeNet-5进行手写数字(MNIST)辨识为例说明。 从Fig. 2中可看到,一张32x32像素的灰阶影像,经过多次卷积、池化后,最后展平、全链接后即可得到十个数字的置信度(机率),而数值最高的就是推论出来的结果。 这个小模型权重值就有6万多个,总MAC计算次数更高达42万多次,其中前两段的卷积计算更占了36万多次,超过85%。

Fig. 2 LeNet-5卷积神经网络结构图[2]。 (OmniXRI整理绘制, 2021/9/18)
从Fig. 3中可看到CNN所应用到的基本元素原理,包括卷积、池化、展平、全连结及Softmax输出。 其中最耗费计算量的就是卷积。 如Fig. 3左上图标,一个3x3的卷积核(Kernel)要计算一个卷积值出来就要使用9次乘法和9次乘法。 一个3x3的卷积核对4x4矩阵进行卷积就要36次乘法和36次乘法才能完成。 若将其等比放大,大家就能理解为何需要极高的算力才能完成卷积神经网络的计算了。
因此如何让这样的乘积累加工作大量平行化、高速化,就变成tinyML成功导入的关键了。
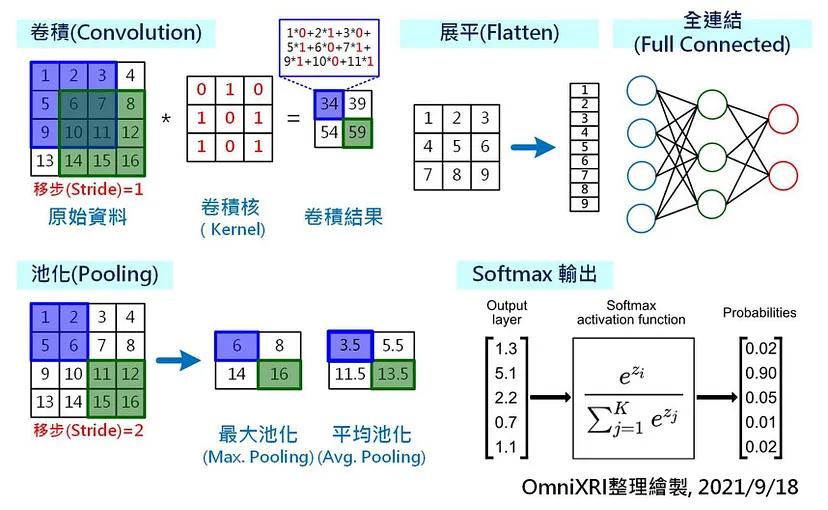
Fig. 3 卷积神经网络基本元素说明图[2]。 (OmniXRI整理绘制, 2021/9/18)
目前要让MAC计算加快的思路大概有「提高工作时脉速度」、「平行/向量指令集加速」、「多核心加速」、「NPU神经网络加速器」、「SOC混合型芯片(MPU)」及「AutoML模型优化平台」等方式,以下就对较具代表性的产品及技术做一简单说明。
2.1 提高工作时脉速度
从[1]文中可知,从第一颗MCU上市至今已四十多年。 早期的Intel 8048工作时脉速度(Clock Speed)只有6 MHz,执行一个指令要6个周期,实际运算速度只有1 MIPS(每秒百万指令)。 大家常用的Arduino Uno R3的ATmega328P则有16 MIPS。 到现在ST的STM32H7工作时脉已达550 MHz,执行速度增加不止500倍。 所以相同的程序不用作任何修改,换一个工作时脉快一点的MCU就能让乘加速度提升。
早期的MCU只能处理整数(INT8)的加法及乘法,但加法只需一个指令周期,而乘法则依不同设计方式需要3~32个指令周期才能完成运算。 2004年arm[3]推出Cortex-M3后才开始有1个指令周期的乘法指令出现。 不过要到了arm Cortex-M4后才开始能支持单精度浮点数(FP16)加法及乘法指令。
早期在处理一些声音信号时,常需要用到像快速傅立叶转换(FFT)的计算,由于需要大量的乘加计算(MAC),于是有了专用的数字信号处理器(Digital Signal Processor, DSP) 出现。 arm在Cortex-M3推出时就在指令集中加入32位乘加指令「MLA」,即可让R4=R1∗R2+R3R4=R1∗R2+R3这样的乘加运算在一个指令周期完成,企图取代DSP的市场。 后来更在Cortex-M4扩增了更多DSP指令集(含32/64bit浮点数及饱和运算指令),使得MCU的运算能力有了大幅提升。 更多关于arm Cortex-M指令集说明可参考[2]中「[Day 06]tinyML的重要推手arm Cortex-M MCU」。
因此MCU工作时脉的提升及乘加指令的出现,展开了MAC加速计算的第一步。 此时在相同工作时脉下至少提升二倍速度。
另外这里会衍生一个评估算力的单位OPS(Operation per Sencod),通常会以每秒百万次(106106)操作MOPS或每秒十亿次(109109)操作GOPS或每秒一兆次(10121012)操作TOPS来表示。 但至于一次操作是只有表示一次加法或者只有一次乘法,还是一次操作就含一次乘加运算,会依不同硬件会不同表示方式,运算能力差一倍,要特别注意。
2.2 平行/向量指令集加速
有了乘加指令后,下一步就是如何在一道指令中完成更多的乘加动作,于是就有了单指令多数据流(Single Instruction Multiple Data, SIMD)的概念被推出。 如Fig. 4右侧上方所示,如果要对4组数据进行加法时,需要执行4次加法。 如Fig. 4右侧下方所示,若采用SIMD做法时,只要准备好4笔被加数及4笔加数,则一道指令就能完成4组加法,速度瞬间提升4倍。
不过这种作法主要适用于高位元数指令集,如32bit指令集,就能将其拆成2个16bit或4个8bit的数值运算。 若为更高字节数如64/128/256/512bit就能拆解成更多组的数据同时运算。 这里以知名MCU arm Cortex-M系列为例,如Fig. 3左侧所示,Cortex-M3 v7-M指令集就开始支持乘加指令,如MLA。 到了Cortex-M4/M7就能支持扩展DSP V7E-M指令集(含SIMD指令集),所以目前市售最常见的tinyML开发板多半以Cortex-M4/M7为主流。 最新的Cortex-M55更能支持矢量扩充(MVE)指令集(类似Cortex-A的高阶SIMD-NEON矢量运算指令集)[2]。

Fig.4 arm Cortex指令集比较及SIMD概念图。 (OmniXRI整理制作,2022/10/17)
近年来RISC-V技术兴起,所以也有很多MCU开始采用,不再让arm Cortex-M系列专美于前。 RISC-V除了基本计算的指令集外,也有DSP扩充指令集(P Extention, RVP)和向量扩充指令集(V Extension, RVV)加入。 如Fig. 5所示,RVP就是SIMD指令,可将两个16bit运算合并在一个32bit指令运算,如此就能得到2倍的运算效率。 而RVV就类似arm NEON矢量运算指令集,可指定一堆特定矢量暂存器,一口气把所有运算完成,达到更高倍率的运算能力。
目前台湾晶心科技[4]为RISC-V IP主要供应商,其AX25系列可支持RVP指令集,而NX27V系列则可支持RVV 1.0指令集。 而知名RISC-V芯片供应商SiFive [5] 的X280系列亦可支持RVV指令集,
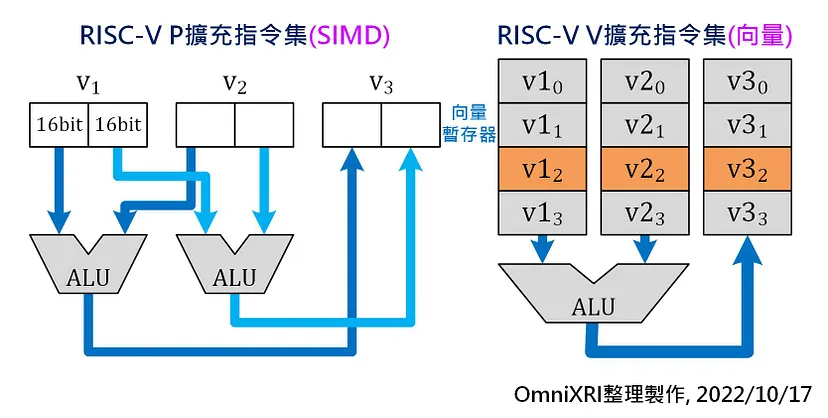
Fig.5 RISC-V RVV及RVP扩充指令集示意图。 (OmniXRI整理制作,2022/10/17)
2.3 多核心加速
另一种增加运算速度的思路就是增加MCU核心数。 一般来说一个MCU只有一个核心,但随着半导体技术演进,同质多核心及大小核心甚至混合arm和RISC-V的MCU也陆续出现。 这样的作法除可增加运算速度外,通常也有分工作业的意图,甚至可以利用其中一个核心来运行小型操作系统(如arm Mbed, RTOS, ROS等),达到多工运行的目的。 以下就简单列举几个相关产品,如Fig. 6所示。

Fig. 6 多核心单芯片相关产品。 (OmniXRI整理制作, 2022/10/17)
2.3.1 Raspberry RP2040系列
树莓派基金会于2021年发行了Raspberry Pi Pico,其核心芯片RP2040号称只要一美金,于是开始有很多厂商以此设计了很多开发板,由Fig.。 这款芯片主要是使用arm Cortex-M0+,它具有2个核心,工作时脉高达133MHz,搭配264KB SRAM, 2MB Flash,可以运行MicroPython, C++,甚至有人把RTOS移植到开发板上。
RP2040非常受欢迎,目前有多款开发板都能支持tinyML开发,以下就简单列出几款。 如果不太在意计算速度时,Pico4ML-BLE也是有搭配图像传感器,可以完成一些tinyML影像分类应用。
- Raspberry Pi Pico / Pico W(https://www.raspberrypi.com/products/raspberry-pi-pico/) [6]
- Arduino Nano RP2040(https://docs.arduino.cc/hardware/nano-rp2040-connect) [7]
- Arducam Pico4ML-BLE(https://www.arducam.com/arducam-pico4ml-ble-version/) [8]
- 硅递(Seeed) XIAO RP2040(https://www.seeedstudio.com/XIAO-RP2040-v1-0-p-5026.html) [9]
- 微雪(Waveshare) RP2040-Zero(https://www.waveshare.net/shop/RP2040-Zero.htm) [10]
2.3.2 晶心科技AX45MP系列
由于RISC-V指令集部份采取开源方式在推广,所以有很多硅智财(IP)厂商协助将其整合成可以生产的芯片。 由于设计上具有很高弹性,所以根据客户需求从2~1000核心皆可,很适合用于AI加速计算使用。 目前台湾晶心科技为主要RISC-V IP供应商,其AX45MP系列[11]就是64bit 4核心的标准设计,方便用户直接采用。
2.3.3 Sony Spresense
现有市售开发板中,索尼 Spresnese [12] 大概是核心数最多的单芯片了。 它拥有6个arm Cortex-M4核心,工作时脉高达156MHz,搭配有1.5MB SRAM, 8MB Flash,6核心共享。 这款开发板可搭配影像感测器,完成一些简易型tinyML影像分类及对象侦测工作。 使用时,可以选择使用多个核心加速同一个模型的推论,或者让多个核心分别同时处理不同的模型,或者部份核心用于推论而部份核心用于处理其它工作皆可。
2.4 NPU神经网络加速器
透过上面的介绍,虽然已可加速MAC的计算数倍到数十倍,但面对像CNN这样庞大的计算量时仍明显不足,尤其是在影像类应用。 一般如果是在台式机或笔电上开发或执行AI应用时可以使用GPU来帮忙加速运算,但在小型边缘智能装置上通常没有GPU,此时就需要额外加装 神经网络加速器(Neural Network Processing Unit, NPU) ,即俗称的AI芯片,来代替GPU。 此类芯片就是专门用来处理大量乘加计算用的,一道指令就能同时执行数百到数千个乘加计算。 依不同芯片用途,有些只能处理8bit整数(INT8),有些能处理16/32bit浮点数(FP16/FP32)计算,甚至有些可以处理最新的BF16格式浮点数。
目前常见的通用型AI推论芯片有耐能(Kneron)的KL520 / KL720 / KL530 [13] ,Intel 神经运算棒2(Myraid X, Neural Compute Stick 2, NCS2)[14],Google Edge TPU Coral [15] 、嘉楠勘智K210 / K510[16]等。 这些芯片除了可和MCU直接焊在同一块板子外,为了方便使用也常制作成小型适配器,如USB, mini-PCIE, M.2等。
几年前各家IC设计公司看到边缘智能设备(Edge AI Device)和智慧物联网(AIoT)离线计算风潮的兴起,于是就开始着手设计把MCU和NPU塞入同一颗芯片中,让使用者能开发出面积更小的板子,同时拥有更高的算力,更低的功耗及价格。 经过这一、两年的努力,这些芯片及相关开发板已陆续上市,相信在各位开发者的努力下,明年应会有崭新的tinyML及AIoT生态系产生。 以下就把目前已官宣或上市的产品简单盘点一下,让有兴趣使用的朋友能提早做准备,迎接新的蓝海市场。
2.4.1 ALIF Ensemble系列
arm于2020年2月宣布推出Cortex-M55 MCU + Ethos U55 NPU的IP组合,经过了两年,ALIF推出了Ensemble系列产品[17],其中整合了1到4核心的MCU, NPU及MPU,如下所示。
- E1: (M55 @160MHz + U55 @128MAC/c)
- E3: (M55 @160MHz + U55 @128MAC/c) + (M55 @400MHz + U55 @256MAC/c)
- E5: (M55 @160MHz + U55 @128MAC/c) + (M55 @400MHz + U55 @256MAC/c) + (A32 @800MHz)
- E7: (M55 @160MHz + U55 @128MAC/c) + (M55 @400MHz + U55 @256MAC/c) + (A32 @800MHz)x2 以MobileNet V2进行推论测试时,一组M55+U55就比前一代的Cortex-M快了800倍,也比单独M55时快了78倍。
目前E7芯片也有推出对应的模组板及扩充底板,如Fig. 7所示。 不过目前仅在推广阶段,想要使用要直接和原厂连络。

Fig.7 ALIF Ensemble E7模块板及扩展底板[18]。 (OmniXRI整理制作,2022/10/17)
2.4.2 NXP MCX-N系列
据NXP官网释出资料[22]及相关报道[23],如Fig. 9所示,MCX系列包含四个分支,而MCX-N即MCU + NPU系列。 其中MCU主核心为arm Cortex-M33(ARMv8-M指令集),工作时脉150M~250MHz,具镇搭配有1MB SRAM, 4MB Flash。 另外自带NPU(32~2K OP/c),其效能比单独M33运行快至少30倍。 目前该系列产品仅有官网介绍及部份商品在相关展会中推出,至于MCX-N何时会上市,看来就只能再等等了。

Fig.9 NXP MCX-N基本规格及NPU效能表[22]。 (OmniXRI整理制作,2022/10/17)
2.4.3 NXP i.MX 系列
NXP早期有和Google的Edge TPU(Coral)合作,用两颗芯片的方式做成小型AI加速计算开发模块及开发板。 如Fig. 10所示,目前较高阶的 i.MX 8M Plus[24]和 i.MX 93[25]系列除了主核心arm Cortex-A本身的NEON(高阶SIMD/向量运算)加速外,皆已内建NPU,以满足更高算力需求。 以下就简单比较一下其差异。
- i.MX 8M Plus CPU: arm Cortex-A53 x4, 1.8GHz, Cortex-M7 x1, 800MHz
GPU: GC7000, 16GFLOPS
NPU: 2.3TOPS,支持ONNX, TensorFlow Lite, DeepViewRT。
- i.MX 93 CPU: arm Cortex-A55 x2, 1.7GHz, Cortex-M33 x1, 250MHz
GPU: 2D GPU
NPU: arm Ethos U65,支持TensorFlow Lite。
另外CPU Cortex-A部份亦可用于AI计算,i.MX 8M Plus可支持PyTorch, ONNX, TensorFlow Lite, OpenCV, DeepViewRT,但i. MX 93只支持TensorFlow Lite和 DeepViewRT。 TensorFlow Lite软件堆叠(software stack)在处理时会依CPU(Cortex-A), NPU+GPU(i.MX 8 series), Ethos-U(i.MX 93)等不同硬件加速运算采用不同的处理方式。
目前i. MX 8M Plus已在市面上可买到相关晶片及开发板,而i. MX 93可能还要再等等。 更多关于i. MX系列有关机器学习相关内容,可参考官方文件[26]说明。

Fig.10 NXP i.MX 8M Plus和 i.MX 93。 (OmniXRI整理制作,2022/10/17)
2.5 REALTEK RTL8735B
瑞昱(Realtek)是台湾少数能提供MCU + RF解决方案的芯片供应商,以往的Ameba系列应用在物联网(IoT)相当受到大家欢迎。 最近他们出了Ameba Pro 2系列[27],以RTL8735B为主要芯片,其核心为arm 32bit v8M指令集MCU(官网未说明,猜想可能是M33、M35P或M55之类的),工作时脉最高可达500MHz,搭配768KB ROM, 512K RAM, DDR2 128MB。 晶片有支持WiFi 2.4GHz/5GHz, BLE4.2。 另外自带Integrated Intelligent Engine(即NPU)算力有0.4TOPS。 如Fig. 10所示,目前提供两种开发板,AMB82(大板,全引脚功能)及AMB82-MINI(小板,可直接摄影机模组,具SD卡槽)。

Fig.11 REALTEK Ameba Pro 2开发板示意图。 (OmniXRI整理制作,2022/10/17)
2.6 离线语音识别(MCU+DSP+NPU)
以往智能音箱由于需求明确,就是为了侦测唤醒词(Wakeup Word Detecion, Keyword Spotting),所以就出现了数十家公司设计专门用于唤醒词辨识的AI芯片。 近来为了更弹性应用,于是有了MCU + DSP + NPU三合一的芯片出现,方便达成离线智能语音控制电气产品及互动的目的。 这里简单列举两个产品进行说明,如Fig. 11所示。
普林芯驰(Spacetouch)
智能离线语音交互MCU SPV20系列[28]同时具有CPU、DSP及NPU,以下就简单列出重要规格。
- MCU SiFive E21 RISC-V 32bit核心,工作时脉96MHz,具有硬件乘法器,256KB SRAM,2/4 MB Flash。
- DSP CEVA TL420核心,工作时脉192MHz,48KW DTCM,8KW PTCM,16KW PCache,两个16x16 MAC。
- NPU 8bit 定点数运算,自有算法支持100个语音控制命令,支持CNN, DS-CNN等深度压缩语音识别模型。
杭州国芯(Nationalchip)
GX8009 AI语音SoC芯片 / GX8010 物联网人工智能芯片 [29] ,这两款芯片主要都结合了一个大核MPU、一个小核MCU、DSP及NPU。 以下就列出重要规格。
- MPU arm Cortex-A7 1GHz
- MCU 32bit RISC-V 150MHz
- DSP Tensilica Hifi-4, 400MHz
- NPU MPU内含64xMAC, MCU内含32xMAC,可用于矩阵乘加、卷积、点乘等功能。更多GX8009/8010技术文件可参考官方文件[30]。
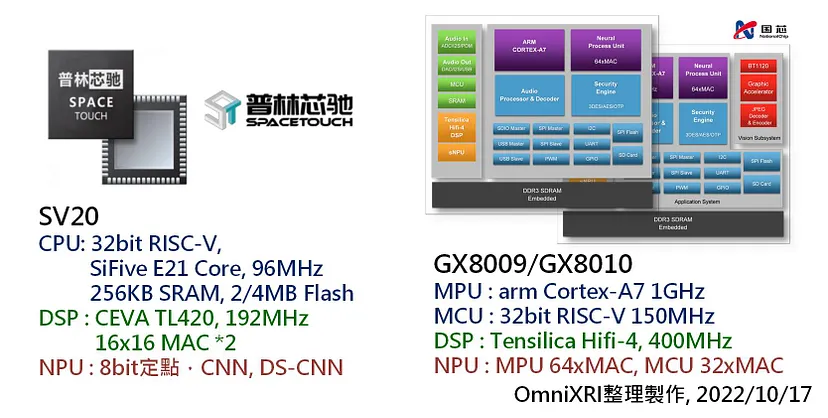
Fig.12 普林芯驰及杭州国芯智能语音芯片。 (OmniXRI整理制作,2022/10/17)
2.7 ST STM32N6
据报导[31]ST将于2022年底推出MCU + NPU(ST Neural-ART)的解决方案,名称为「STM32N6」,报导中推估可能arm Cortex-M55 + Ethos U55的组合,不过目前ST官方并没有释出更进一步说明,就有待时间来证明。
3 SOC混合型芯片(MPU)
本文主要是介绍以MCU等级的AI应用为主,以上内容只适用于较小型的Edge AI及AIoT产品,但如果需要大一些的AI应用,就要用到 单板微电脑(Single Board Computer, SBC) (如树莓派、Nvidia Jetson Nano, Asus TinkerBoard或一般手机、平板等)所使用的芯片, 此时主要核心芯片多半是较高等级的微处理器(Micro Processing Unit, MPU) ,如arm Cortex-R, Cortex-A等,或者是 系统级芯片(System on Chip, SoC) (内含多核CPU, DSP, GPU, NPU, ISP等),如联发科天玑、Google Pixel、 Apple Bionic等。
当然随着主核心芯片算力提升,AI应用的规模加大(如影像分割、姿态估测、对话机器人等),内建NPU也变成基本配备。 而这类的NPU大多数也能支持常见的TensorFlow, PyTorch, ONNX等AI框架,算力也至少有1TOPS以上。 如Fig. 13所示,以下就简单列举几个自带NPU之MPU或SoC及对应的开发板。
- 联发科(MediaTek) 天玑Dimensity 720/MT685332
- CPU: arm Cortex-A76 x4 2GHz, Cortex-A55 x4 2GHz
- GPU: arm Mali-G57 MC3
- NPU: 1TOPS
- 对应开发板: XY6853A 5G安卓智能核心板33
- 瑞芯微电子(Rockchip) RK3399PRO34
- CPU: arm Cortex-A72 x2, 1.8GHz, Cortex-A53 x4, 1.4GHz
- GPU: arm Mali-T860 MP4, 800MHz
- NPU: 1920 INT8 MACs, 192 INT16 MACs, 64 FP16 MACs
- 支持TensorFlow / TF Lite / Caffe / ONNX / Darknet AI框架, Android NN API / RKNN / Rock-X SDK AI工具
- 对应开发板: Bearkey TB-96AI RK3399Pro核心板35
- 瑞芯微电子(Rockchip) RK3588S36
- 全志(Allwinner) V85339
- CPU: arm Cortex-A7 1.0GHz, RISC-V E907 600MHz
- NPU: 1TOPS
- 支援OpenCV, TensorFlow, PyTorch, Caffe TFLite, Darknet Theano AI框架,OpenCL, OpenVX, Android NN, ONNX API。
- 对应开发板: V853开发板40
- 瑞萨(Renesas) RZ/V2MA41
- CPU: arm Cortex-A53 x2, 1.0GHz
- NPU: DRP-AI 1.0TOPS/W (TinyYoloV3 52fps)
- 支持 DRP-AI TVM / ONNX / PyTorch / OpenCV
- 对应开发板: SHIMAFUJI RZ/V2MA evaluation kit42

Fig.13 常见自带NPU之MPU或SoC开发板。 (OmniXRI整理制作,2022/10/17)
4 AutoML模型优化平台
在MCU上运行AI时,有时常因模型太大塞不进,或者推论所需记忆不足,或者推论速度不够快,此时可能就需要进行模型优化工作。 一般模型优化常见作法有参数量化、模型剪枝、权重共享、知识蒸馏等手法,但这些工作太过复杂,非一般MCU或AI工程师有办法独立完成,因此就要借助专业的AutoML工具来帮忙优化。 所谓AutoML就是通过程序自动找出合适的模型架构、超参数,并自动重新训练得到多组理想的模型,让用户能依模型大小、内存需求、推论精度或速度来选择最终要部署在MCU的模型。
目前已有许多tinyML开发平台厂商提供此类AutoML模型优化工具[43],如Fig. 14所示。 如果想更进一步了解其原理、操作模式及推论效果,可自行点击下列清单连结。
- Edge Impulse / EON Tuner(https://docs.edgeimpulse.com/docs/edge-impulse-studio/eon-tuner)
- GreenWaves / GAP_SDK(https://github.com/GreenWaves-Technologies/gap_sdk)
- Neuton(https://neuton.ai/)
- Stream Analyze(https://streamanalyze.com/)
- Google / QKeras(https://github.com/google/qkeras)
- SensiML(https://sensiml.com/)
- imagimob(https://www.imagimob.com/)
- Qualcomm / AIMET(https://github.com/quic/aimet)
- Qeexo / AutoML(https://qeexo.com/)
- NotaAI / NetsPresso(https://www.netspresso.ai/)
- OmniML(https://www.omniml.ai/)

Fig.14 常见提供AutoML的tinyML平台厂商。 (OmniXRI整理制作,2022/10/17)
5 小结
要在MCU上运行AI模型要克服的工作很多,从算力、内存大小、储存空间、功耗、价格等。 透过本文的介绍相信大家都已对如何克服算力问题已有一些认识。 随着MCU内建NPU的产品陆续问世,算力大幅提升,相信不久的将来,离线(不上网)就能完成AI运算就不再是遥不可及的梦想,tinyML也能从此迈向新的里程碑了。
6 参考文献
[1] 许哲豪,当智慧物联网(AIoT)遇上微型机器学习(tinyML)是否会成为台湾单芯片(MCU)供应链下一个新商机!?
https://omnixri.blogspot.com/2021/09/aiottinymlmcu.html
[2] 许哲豪,iThome 2021 (13届) 铁人赛【arm platforms组】完赛记录 ─ 争什么,把AI和MCU掺在一起做tinyML就对了!
https://omnixri.blogspot.com/2021/10/ithome-2021-13-arm-platforms-aimcutinyml.html
[3] arm — 产品 — 处理器IP
https://www.arm.com/zh-TW/products/silicon-ip-cpu
[4] 晶心科技(Andes Tech.) — Processors
http://www.andestech.com/tw/ 产品与解决方案/andescore-processors/
[5] SiFive — Product — Core IP
https://www.sifive.com/risc-v-core-ip
[6] Raspberry Pi Pico / Pi Pico W
https://www.raspberrypi.com/products/raspberry-pi-pico/
[7] Arduino Nano RP2040 Connect
https://docs.arduino.cc/hardware/nano-rp2040-connect
[8] Arducam Pico4ML-BLE
https://www.arducam.com/arducam-pico4ml-ble-version/
[9] 硅递(Seeed) XIAO RP2040
https://www.seeedstudio.com/XIAO-RP2040-v1-0-p-5026.html
[10] 微雪(Waveshare) RP2040-Zero
https://www.waveshare.net/shop/RP2040-Zero.htm
[11] 晶心(AndesCore) AX45MP
https://www.andestech.com/en/products-solutions/andescore-processors/riscv-ax45mp/
[12] Sony Spresense
https://developer.sony.com/develop/spresense/
[13] 耐能(Kneron) AI System on Chip (SoC)
https://www.kneron.com/tw/page/soc/
[14] Intel Neural Compute Stick 2 (NCS2)
https://www.intel.com/content/www/us/en/developer/tools/neural-compute-stick/overview.html
[15] Google Edge TPU Coral — Products
https://coral.ai/products/
[16] 嘉楠(Canaan) — 勘智AI K210/K510
https://canaan-creative.com/product/kendryteai
[17] ALIF Semiconductor — Ensemble
https://alifsemi.com/ensemble/
[18] Edge Impulse Blog — Announcing Official Support for the Alif Ensemble E7 Development Kit
https://www.edgeimpulse.com/blog/announcing-official-support-for-the-alif-ensemble-e7-development-kit
[22] NXP — MCX General-Purpose MCUs
https://www.nxp.com/products/processors-and-microcontrollers/arm-microcontrollers/general-purpose-mcus/mcx-cortex-m:MCX-MCUS
[23] Electronics Weekly — Embedded World: NXP MCX MCUs
https://www.electronicsweekly.com/news/products/micros/embedded-world-nxp-replaces-lpc-kinetis-new-mcu-families-2022-06/
[24] NXP — Processors and Microcontrollers — i.MX 8M Plus
https://www.nxp.com/products/processors-and-microcontrollers/arm-processors/i-mx-applications-processors/i-mx-8-applications-processors/i-mx-8m-plus-arm-cortex-a53-machine-learning-vision-multimedia-and-industrial-iot:IMX8MPLUS
[25] NXP — Processors and Microcontrollers — i.MX 93
https://www.nxp.com/products/processors-and-microcontrollers/arm-processors/i-mx-applications-processors/i-mx-9-processors/i-mx-93-applications-processor-family-arm-cortex-a55-ml-acceleration-power-efficient-mpu:i.MX93
[26] NXP — i.MX Machine Learning User’s Guide
https://www.nxp.com/docs/en/user-guide/IMX-MACHINE-LEARNING-UG.pdf
[27] Realtek — AmebaPro2 Boards
https://www.amebaiot.com/zh/amebapro2/
[28] 普林芯驰 — 智能离线语音交互MCU http://www.spacetouch.co/product/bendiyuyin/
[29] 杭州国芯 — 产品中心 — 人工智能
http://www.nationalchip.com/index.php/products/2
[30] 杭州国芯 — 产品简介 — GX8010
https://ai.nationalchip.com/docs/gx8010/
[31] eeNews Europe — ST to launch its first neural microcontroller with NPU
https://www.eenewseurope.com/en/st-to-launch-its-first-neural-microcontroller-with-npu/
[32] 联发科(MediaTek) 天玑Dimensity 720/MT6853
https://www.mediatek.tw/products/smartphones-2/dimensity-720
[33] XY6853A 5G安卓智能核心板
http://www.new-mobi.com/news/74-cn.html
[34] 瑞芯微电子(Rockchip) RK3399PRO
https://www.rock-chips.com/a/en/products/RK33_Series/2018/0130/874.html
[35] Bearkey TB-96AI RK3399Pro核心板
https://www.bearkey.com.cn/products/TB-96AI.html
[36] 瑞芯微电子(Rockchip) RK3588S
https://www.rock-chips.com/a/en/products/RK35_Series/2022/0926/1660.html
[37] Khadas Edge2
https://www.khadas.com/edge2
[38] Firefly ROC-RK3588S-PC
https://www.t-firefly.com/product/industry/rocrk3588spc
[39] 全志(Allwinner) V853
https://v853.docs.aw-ol.com/
[40] V853开发板
https://v853.docs.aw-ol.com/hard/hard_1board/
[41] 瑞萨(Renesas) RZ/V2MA
https://www.renesas.com/us/en/products/microcontrollers-microprocessors/rz-cortex-a-mpus/rzv2m-dual-cortex-a53-lpddr4x32bit-ai-accelerator-isp-4k-video-codec-4k-camera-input-fhd-display-output
[42] SHIMAFUJI RZ/V2MA evaluation kit
http://www.shimafuji.co.jp/en/products/2044
[43] tinyML — State of the tinyAutoML Market 2022
https://www.tinyml.org/static/3eccc61369f52aaeb2d8eea64e13e6e7/State-of-the-tinyAutoML-Market.pdf