如何从零开始进行leetcode刷题。
算法攻略从零到一(cpp版)
1 前言
虽然C++是⼀⻔⾯向对象语⾔,但是算法题的基本思维方式是面向过程式,也就是针对算法题我们是不需要掌握面向对象部分(继承、封装、多态)。只需要掌握刷算法的时候需要⽤到的部分(基本输⼊输出、STL标准模板库、string字符串等)。
使用C++刷题有几大好处:
- 方便的输入输出;C++的
cout、cin不再像C语言里面的输入输出scanf、printf那样需要自己写明变量的类型,比如scanf("%d", &n);printf("%d", n);,直接cin >> n;cout << n; - 更强大的字符串处理;C++的
string字符串类提供了强大的字符串处理功能,不再像C语言里面的字符数组,处理起来比较繁琐; STL模板库;STL的动态数组vector、集合set、映射map、栈stack、队列queue、位运算bitset,以及算法库#include <algorithm>的sort排序算法函数模板等等,都极大提高了我们做题的效率;
整理自网络,非商业用途,侵权联系删除。
2 算法基础之C++
2.1 输入输出
leetcode平台是不需要我们自己写数据输入的,只需要在下图的红色文本框中写自己的解题代码就行。
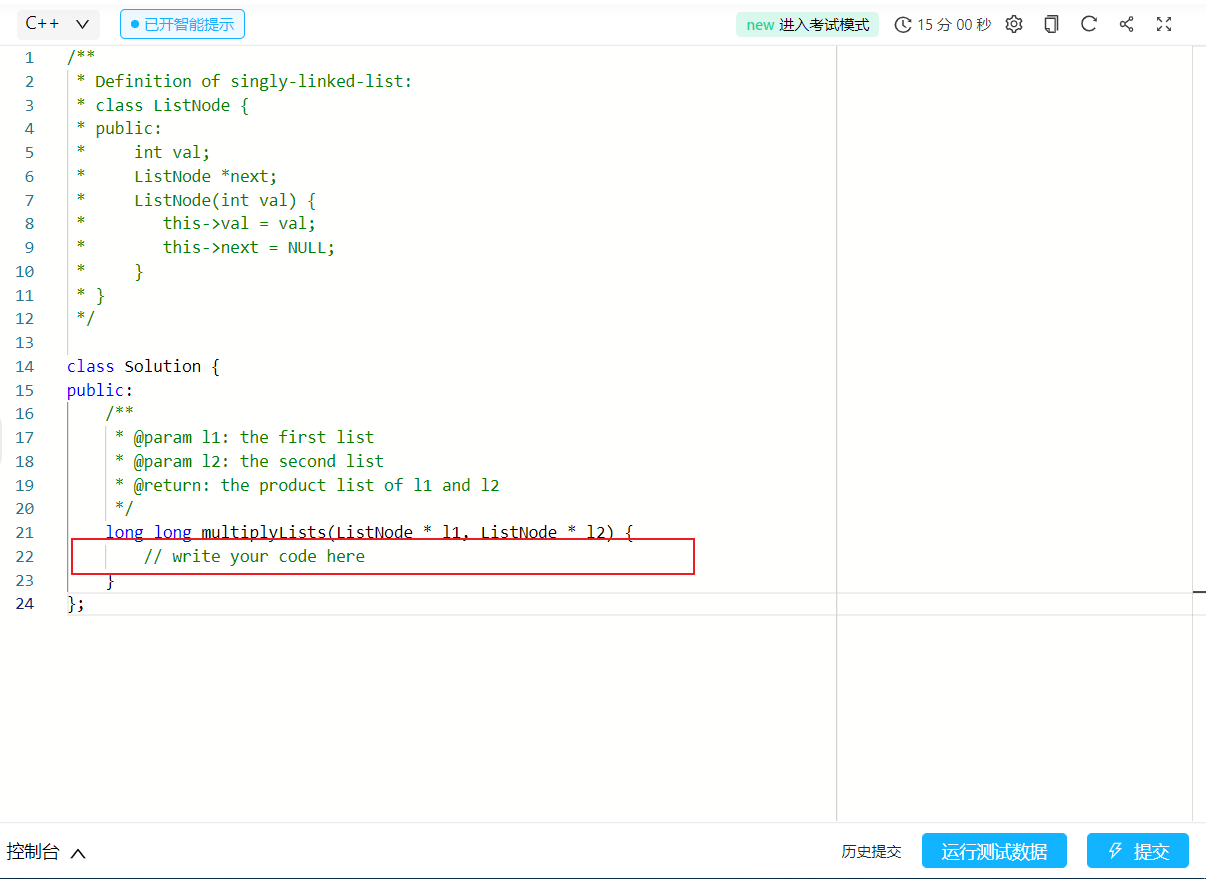
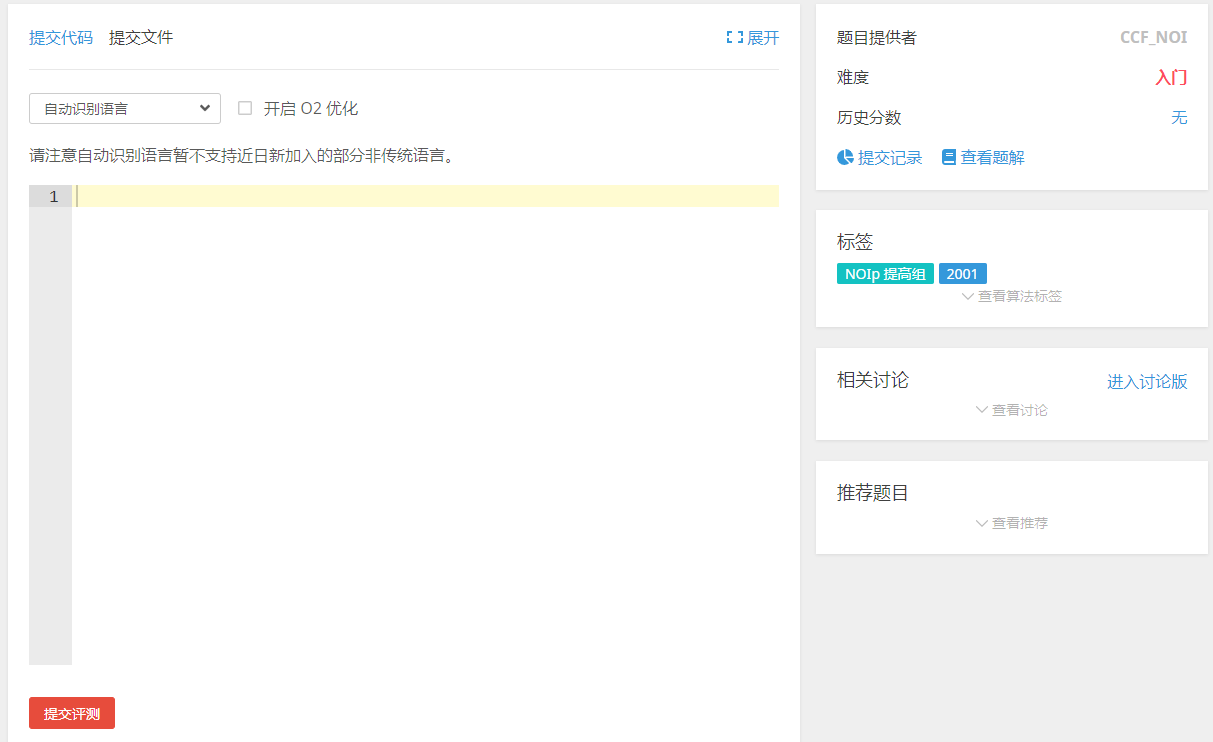
然而在其他的OJ平台上刷题,是需要自己写输入环境的,比如下面的洛谷平台下。

然后在网页编辑框填写自己的代码提交评测。
2.1.1 整数输入问题
- 最简单的输入
//最简单的输入,输入单行
Sample Input 1 2
Sample Output 3
#include <iostream>
using namespace std ;
int main ()
{
int a , b ;
cin >> a >> b ;
cout << a + b << endl ; //对其他题目,换成要求的复杂处理与输出
return 0 ;
}
- 输入多行数时,直到读至输入文件末尾(
EOF)为止
输入多行数时,直到读至输入文件末尾(EOF)为止 说明1:当读到输入结束时,cin » a » b返回 0,循环也结束。 说明2:在调试程序时,键盘输入的数据,用CTRL-Z(即按住CTRL键不放,再按下Z)组合作为输入结束,此谓键盘输入设备的“文件末尾”。 重点掌握
Sample Input 1 5 10 20 400 516
Sample Output 6 30 916
#include <iostream>
using namespace std ;
int main ()
{
int a , b ;
while ( cin >> a >> b ) //当题目输入行数不确定时使用此方法
{
cout << a + b << endl ;
}
return 0 ;
}
- 多组由两个整数(a和b)构成的输入,a和b之间用空格隔开,每组输入单独占一行。
多组由两个整数(a和b)构成的输入,a和b之间用空格隔开,每组输入单独占一行。 当输入为 0 0 时,输入结束。 Sample Input 1 5 10 20 0 0 Sample Output 6 30
#include<iostream>
using namespace std ;
int main ()
{
int a , b ;
while ( cin >> a >> b &&( a || b ))
{
cout << a + b << endl ;
}
return 0 ;
}
- 第一行是数据的组数N,从第二行是N组由两个整数(a和b)构成的输入,a和b之间用空格隔开,每组输入单独占一行
第一行是数据的组数N, 从第二行是N组由两个整数(a和b)构成的输入,a和b之间用空格隔开,每组输入单独占一行 重点掌握
Sample Input 2 1 5 10 20 Sample Output 6 30
#include <iostream>
using namespace std ;
int main () {
int a , b , n ;
cin >> n;
for (int i = 0 ; i < n ; i ++)
{
cin >> a >> b ; //cin以空格或者回车作为输入输出分隔符
cout << a + b << endl ;
}
return 0 ;
}
- 利用文件重定向提高调试效率
#include<iostream>
#include<cstdio>
using namespace std ;
int main ()
{
freopen ( "input.txt" , "r" , stdin ); // 将输入重定向到文件 input.txt (注意文件路径)
int a , b ;
cin >> a >> b ;
cout << a + b << endl ;
return 0 ;
} // 在运行程序前,将本该由键盘输入的数据,写到文件 input.txt 中。而在运行程序时,数据将不再需要人去输入
2.1.2 读取和解析标点字符(如逗号)分隔数据
- 读取以逗号间隔的数字到数组中
处理输入问题:读取以逗号间隔的数字到数组中
例:
输入:1,12,123
数组a:a[0] = 1,a[1] = 12, a[2] = 123
#include <vector>
#include <iostream>
#include <sstream>
#include <string>
using namespace std ;
int main ()
{
vector < int > a ;
string s ;
cin >> s ; //读取输入字符串到s
stringstream input ( s ); //将字符串s转化为流
string numstr ;
while ( getline ( input , numstr , ',' )) //按逗号分隔为字符串( getline每次读一个 )
{
a . push_back ( stoi ( numstr ));
}
return 0 ;
}
思路:使用 getline 和 stringstream 以 ‘,’ 为分隔符来切分数据 ,然后使用标准库 string 的数值转换函数例如字符串转整形 stoi 进行解析。注意: 当数据以空格分隔时,可以直接用cin来读入!
2.2 String类
string 类,使得字符串的定义、拼接、输出、处理都更加简单。不过 string 只能⽤ cin 和 cout 处理,⽆法⽤ scanf 和 printf 处理:
string s = "hello world"; // 赋值字符串
string s2 = s;
string s3 = s + s2; // 字符串拼接直接⽤+号就可以
string s4;
cin >> s4; // 读⼊字符串
cout << s; // 输出字符串
⽤ cin 读⼊字符串的时候,是以空格为分隔符的,如果想要读⼊⼀整⾏的字符串,就需要⽤ getline 。
此外string的长度可以用string s; s.length(); s.size()获取,这两个获取长度的函数功能是一样的。与C语言的char []还要考虑尾部的\0字符,string里面是多少字符就是多少,当然也包括''字符。
string s; // 定义⼀个空字符串s
getline(cin, s); // 读取⼀⾏的字符串,包括空格
cout << s.length(); // 输出字符串s的⻓度
string 中还有个很常⽤的函数叫做 substr ,作⽤是截取某个字符串中的⼦串,⽤法有两种形式:
string s2 = s.substr(4); // 表示从下标4开始⼀直到结束
string s3 = s.substr(5, 3); // 表示从下标5开始,3个字符
2.3 STL
2.3.1 STL之动态数组vector(⽮量)
之前C语⾔⾥⾯⽤ int arr[] 定义数组,它的缺点是数组的⻓度不能随⼼所欲的改变。而vector它能够在运⾏阶段设置数组的⻓度、在末尾增加新的数据、在中间插⼊新的值、⻓度任意被改变。它在头⽂件 vector ⾥⾯,也在命名空间 std ⾥⾯,所以使⽤的时候要引⼊头⽂件 #include <vector> 和 using namespace std;
vector 、 stack 、 queue 、 map 、 set 这些在C++中都叫做容器,这些容器的⼤⼩都可以⽤ .size() 获取到,就像 string s 的⻓度⽤ s.length() 获取⼀样。只是对于string字符串我们一般是用.length(),而对于容器类我们一般用.size()。
#include <iostream>
#include <vector>
int main() {
vector<int> v1; // 定义⼀个vector v1,定义的时候没有分配⼤⼩
cout << v1.size(); // 输出vector v1的⼤⼩,此处应该为0
return 0;
}
vector 可以⼀开始不定义⼤⼩,之后⽤ resize ⽅法分配⼤⼩,也可以⼀开始就定义⼤⼩,之后还可以对它插⼊删除动态改变它的⼤⼩。⽽且不管在 main 函数⾥还是在全局中定义,它都能够直接将所有的值初始化为0(不⽤显式地写出来,默认就是所有的元素为0)。
vector<int> v(10); // 直接定义⻓度为10的int数组,默认这10个元素值都为0
// 或者
vector<int> v1;
v1.resize(8); //先定义⼀个vector变量v1,然后将⻓度resize为8,默认这8个元素都是0
// 在定义的时候就可以对vector变量进⾏初始化
vector<int> v3(100, 9);// 把100⻓度的数组中所有的值都初始化为9
// 访问的时候像数组⼀样直接⽤[]下标访问即可(也可以⽤迭代器访问,下⾯会讲) v[1] = 2;
cout << v[0];
除了可以访问官网查看vector的所有功能,我们下面列举一些常见的方法。
#include <iostream>
#include <vector>
using namespace std;
int main() {
vector<int> a; // 定义的时候不指定vector的⼤⼩
cout << a.size() << endl; // 这个时候size是0
for (int i = 0; i < 10; i++) {
a.push_back(i); // 在vector a的末尾添加⼀个元素i
}
cout << a.size() << endl; // 此时会发现a的size变成了10
vector<int> b(15); // 定义的时候指定vector的⼤⼩,默认b⾥⾯元素都是0
cout << b.size() << endl;
for (int i = 0; i < b.size(); i++) {
b[i] = 15;
}
for (int i = 0; i < b.size(); i++) {
cout << b[i] << " ";
}
cout << endl;
vector<int> c(20, 2); // 定义的时候指定vector的⼤⼩并把所有的元素赋⼀个指定的值
for (int i = 0; i < c.size(); i++) {
cout << c[i] << " ";
}
cout << endl;
//auto此次相当于vector<int>::iterator
for (auto it = c.begin(); it != c.end(); it++) { // 使⽤迭代器的⽅式访问vector
cout << *it << " ";
}
return 0;
}
容器 vector 、 set 、 map 这些遍历的时候都是使⽤迭代器访问的, c.begin() 是⼀个指针,指向容器的第⼀个元素, c.end() 指向容器的最后⼀个元素的后⼀个位置,所以迭代器指针it的for循环判断条件是 it != c.end()。

2.3.2 STL之集合set的使用
set 是集合,⼀个 set ⾥⾯的各元素是各不相同的,⽽且 set 会按照元素进⾏从⼩到⼤排序,以下是 set 的常⽤⽤法:
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> s; // 定义⼀个空集合s
s.insert(1); // 向集合s⾥⾯插⼊⼀个1
cout << *(s.begin()) << endl; // 输出集合s的第⼀个元素 (前⾯的星号表示要对指针取值)
for (int i = 0; i < 6; i++) {
s.insert(i); // 向集合s⾥⾯插⼊i
}
for (auto it = s.begin(); it != s.end(); it++) { // ⽤迭代器遍历集合s⾥⾯的每⼀个元素
cout << *it << " ";
}
cout << endl << (s.find(2) != s.end()) << endl; // 查找集合s中的值,如果结果等于s.end()表示未找到 (因为s.end()表示s的最后⼀个元素的下⼀个元素所在的位置)
cout << (s.find(10) != s.end()) << endl; // s.find(10) != s.end()表示能找到10这个元素
s.erase(1); // 删除集合s中的1这个元素
cout << (s.find(1) != s.end()) << endl; // 这时候元素1就应该找不到啦~
return 0;
}
2.3.3 STL之映射map的使用
map 是键值对,⽐如⼀个⼈名对应⼀个学号,就可以定义⼀个字符串 string 类型的⼈名为“键”,学号 int 类型为“值”,如 map<string, int> m; 当然键、值也可以是其它变量类型。 map 会⾃动将所有的键值对按照键从⼩到⼤排序, map 使⽤时的头⽂件 #include <map> 以下是 map 中常⽤的⽅法:
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> m; // 定义⼀个空的map m,键是string类型的,值是int类型的
m["hello"] = 2; // 将key为"hello", value为2的键值对(key-value)存⼊map中
cout << m["hello"] << endl; // 访问map中key为"hello"的value, 如果key不存在,则返回0
cout << m["world"] << endl;
m["world"] = 3; // 将"world"键对应的值修改为3
m[","] = 1; // 设⽴⼀组键值对,键为"," 值为1
// ⽤迭代器遍历,输出map中所有的元素,键⽤it->first获取,值⽤it->second获取
for (auto it = m.begin(); it != m.end(); it++) {
cout << it->first << " " << it->second << endl;
}
// 访问map的第⼀个元素,输出它的键和值
cout << m.begin()->first << " " << m.begin()->second << endl;
// 访问map的最后⼀个元素,输出它的键和值
cout << m.rbegin()->first << " " << m.rbegin()->second << endl;
// 输出map的元素个数
cout << m.size() << endl;
return 0;
}
2.3.4 STL之栈的使用
栈 stack 在头⽂件 #include <stack> 中,是数据结构⾥⾯的栈。以下是常⽤⽤法:
#include <iostream>
#include <stack>
using namespace std;
int main() {
stack<int> s; // 定义⼀个空栈s
for (int i = 0; i < 6; i++) {
s.push(i); // 将元素i压⼊栈s中
}
cout << s.top() << endl; // 访问s的栈顶元素
cout << s.size() << endl; // 输出s的元素个数
s.pop(); // 移除栈顶元素
return 0;
}
2.3.5 STL之队列queue的使用
队列 queue 在头⽂件 #include <queue> 中,是数据结构⾥⾯的队列。以下是常⽤⽤法:
#include <iostream>
#include <queue>
using namespace std;
int main() {
queue<int> q; // 定义⼀个空队列q
for (int i = 0; i < 6; i++) {
q.push(i); // 将i的值依次压⼊队列q中
}
cout << q.front() << " " << q.back() << endl; // 访问队列的队⾸元素和队尾元素
cout << q.size() << endl; // 输出队列的元素个数
q.pop(); // 移除队列的队⾸元素
return 0;
}
2.3.6 STL之unordered_map和unordered_set的使用
unordered_map 在头⽂件 #include <unordered_map> 中, unordered_set 在头⽂件#include <unordered_set> 中。
unordered_map 和 map (或者 unordered_set 和 set )的区别是, map 会按照键值对的键 key 进⾏排序( set ⾥⾯会按照集合中的元素⼤⼩进⾏排序,从⼩到⼤顺序),⽽ unordered_map (或者 unordered_set )省去了这个排序的过程,如果偶尔刷题时候⽤ map 或者 set 超时了,可以考虑⽤ unordered_map (或者 unordered_set )缩短代码运⾏时间、提⾼代码效率。⾄于⽤法和 map 、set 是⼀样的。
2.3.7 位运算bitset
bitset ⽤来处理⼆进制位⾮常⽅便。头⽂件是 #include <bitset> , bitset 可能在PAT、蓝桥OJ中不常⽤,但是在LeetCode OJ中经常⽤到。⽽且知道 bitset 能够简化⼀些操作,可能⼀些复杂的问题能够直接⽤ bitset 就很轻易地解决。以下是⼀些常⽤⽤法:
#include <iostream>
#include <bitset>
using namespace std;
int main() {
bitset<5> b("11"); //5表示5个⼆进位
// 初始化⽅式:
// bitset<5> b; 都为0
// bitset<5> b(u); u为unsigned int,如果u = 1,则被初始化为10000
// bitset<5> b(s); s为字符串,如"1101" -> "10110"
// bitset<5> b(s, pos, n); 从字符串的s[pos]开始,n位⻓度
for(int i = 0; i < 5; i++)
cout << b[i];
cout << endl << b.any(); //b中是否存在1的⼆进制位
cout << endl << b.none(); //b中不存在1吗?
cout << endl << b.count(); //b中1的⼆进制位的个数
cout << endl << b.size(); //b中⼆进制位的个数
cout << endl << b.test(2); //测试下标为2处是否⼆进制位为1
b.set(4); //把b的下标为4处置1
b.reset(); //所有位归零
b.reset(3); //b的下标3处归零
b.flip(); //b的所有⼆进制位逐位取反
unsigned long a = b.to_ulong(); //b转换为unsigned long类型
return 0;
}
2.3.8 算法库之sort函数
sort 函数在头⽂件 #include <algorithm> ⾥⾯,主要是对⼀个数组进⾏排序( int arr[] 数组或者 vector 数组都⾏), vector 是容器,要⽤ v.begin() 和 v.end() 表示头尾;⽽ int arr[] ⽤ arr 表示数组的⾸地址, arr+n 表示尾部。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool cmp(int a, int b) { // cmp函数返回的值是bool类型
return a > b; // 从⼤到⼩排列
}
int main() {
vector<int> v(10);
for (int i = 0; i < 10; i++) {
cin >> v[i];
}
sort(v.begin(), v.end());// 因为这⾥没有传⼊参数cmp,所以按照默认,v从⼩到⼤排列
int arr[10];
for (int i = 0; i < 10; i++) {
cin >> arr[i];
}
sort(arr, arr + 10, cmp); // arr从⼤到⼩排列,因为cmp函数排序规则设置了从⼤到⼩
return 0;
}
注意: sort 函数的 cmp 必须按照规定来写,即必须只是 > 或者 < ,⽐如: return a > b; 或者 return a < b; ⽽不能是 <= 或者 >= ,(实际上等于号加了也是毫⽆意义, sort 是不稳定的排序),否则可能会出现段错误。
2.3.9 算法库之sort⾃定义cmp函数
sort 默认是从⼩到⼤排列的,也可以指定第三个参数 cmp 函数,然后⾃⼰定义⼀个 cmp 函数指定排序规则。cmp 最好⽤的还是在结构体中,尤其是很多排序的题⽬。⽐如⼀个学⽣结构体 stu 有学号和成绩两个变量,要求如果成绩不同就按照成绩从⼤到⼩排列,如果成绩相同就按照学号从⼩到⼤排列,那么就可以写⼀个 cmp 数组实现这个看上去有点复杂的排序过程:
#include <iostream>
using namespace std;
struct stu { // 定义⼀个结构体stu,number表示学号,score表示分数
int number;
int score; }
bool cmp(stu a, stu b) { // cmp函数,返回值是bool,传⼊的参数类型应该是结构体stu类型
if (a.score != b.score) // 如果学⽣分数不同,就按照分数从⼤到⼩排列
return a.score > b.score;
else // 如果学⽣分数相同,就按照学号从⼩到⼤排列
return a.number < b.number; }
// 有时候这种简单的if-else语句我喜欢直接⽤⼀个C语⾔⾥⾯的三⽬运算符表示~
bool cmp(stu a, stu b) {
return a.score != b.score ? a.score > b.score : a.number < b.number;
}
2.4 cctype头文件里的判断函数
#include <cctype> 本质上来源于C语⾔标准函数库中的头⽂件#include <ctype.h> ,其实并不属于C++新特性的范畴,但是刷题时会经常碰到。
比如下面的代码就是判断一个字符是否是字母
#include <iostream>
#include <cctype>
using namespace std;
int main() {
char c;
cin >> c;
if (isalpha(c)) {
cout << "c is alpha";
}
return 0;
}
不仅仅能判断字⺟,还能判断数字、⼩写字⺟、⼤写字⺟等,总的来说如下:
isalpha字⺟(包括⼤写、⼩写)islower(⼩写字⺟)isupper(⼤写字⺟)isalnum(字⺟⼤写⼩写+数字)isblank(space和\t)isspace( space 、\t、\r、\n)
此外还有两个常用函数,tolower和toupper,作⽤是将某个字符转为⼩写或者⼤写,这样就不⽤像原来那样⼿动判断字符c是否是⼤写,如果是⼤写字符就 c = c + 32; 的⽅法将c转为⼩写字符。
char c = 'A';
char t = tolower(c); // 将c字符转化为⼩写字符赋值给t,如果c本身就是⼩写字符也不变
cout << t; // 此处t为'a'
2.5 算法刷题常用到的c++11特性
2.5.1 auto声明
auto 是C++11⾥⾯的新特性,可以让编译器根据初始值类型直接推断变量的类型。⽐如这样:
auto x = 100; // x是int变量
auto y = 1.5; // y是double变量
在STL中使⽤迭代器的时候, auto 可以代替⼀⼤⻓串的迭代器类型声明
// 本来set的迭代器遍历要这样写:
for(set<int>::iterator it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
// 现在可以直接替换成这样的写法:
for(auto it = s.begin(); it != s.end(); it++) {
cout << *it << " ";
}
2.5.2 for in range 循环
除了像C语⾔的for语句 for (i = 0; i < arr.size(); i++) 这样,C++11标准还为C++添加了⼀种新的for循环⽅式,叫做基于范围(range-based)的for循环,这在遍历数组中的每⼀个元素时使⽤会⽐较简便。⽐如想要输出数组arr中的每⼀个值,可以使⽤如下的⽅式输出:
int arr[4] = {0, 1, 2, 3};
for (int i : arr)
cout << i << endl; // 输出数组中的每⼀个元素的值,每个元素占据⼀⾏
i 变量从数组的第⼀个元素开始,不断执⾏循环, i 依次表示数组中的每⼀个元素。注意,使⽤ int i 的⽅式定义时,该语句只能⽤来输出数组中元素的值,⽽不能修改数组中的元素,如果想要修改,必须使⽤ int &i 这种定义引⽤变量的⽅式。⽐如想给数组中的每⼀个元素都乘以2,可以使⽤如下⽅式:
int arr[4] = {0, 1, 2, 3};
for (int &i : arr) // i为引⽤变量
i = i * 2; // 将数组中的每⼀个元素都乘以2,arr[4]的内容变为了{0, 2, 4, 6}
这种基于范围的for循环适⽤于各种类型的数组,将上述两段代码中的 int 改成其他变量类型如double 、 char 都是可以的。另外,这种for循环⽅式不仅可以适⽤于数组,还适⽤于各种STL容器,⽐如 vector 、 set 等。加上上⾯⼀节所讲的C++11⾥⾯很好⽤的auto声明,将 int 、double 等变量类型替换成 auto ,⽤起来就更⽅便。
// v是⼀个int类型的vector容器
for (auto i : v)
cout << i << " ";
// 上⾯的写法等价于
for (int i = 0; i < v.size(); i++)
cout << v[i] << " ";
2.5.3 to_string
to_string 的头⽂件是 #include <string> , to_string最常⽤的就是把⼀个 int 型变量或者⼀个数字转化为 string 类型的变量,当然也可以转 double 、 float 等类型的变量,这在很多字符串处理的题⽬中很有⽤处,以下是示例代码
#include <iostream>
#include <string>
using namespace std;
int main() {
string s1 = to_string(123); // 将123这个数字转成字符串
cout << s1 << endl;
string s2 = to_string(4.5); // 将4.5这个数字转成字符串
cout << s2 << endl;
cout << s1 + s2 << endl; // 将s1和s2两个字符串拼接起来并输出
printf("%s\n", (s1 + s2).c_str()); // 如果想⽤printf输出string,得加⼀个.c_str()
return 0;
}
2.5.4 stoi、stod
使⽤ stoi 、 stod 可以将字符串 string 转化为对应的 int 型、 double 型变量,这在字符串处理的很多问题中很有帮助。以下是示例代码和⾮法输⼊的处理⽅法:
#include <iostream>
#include <string>
using namespace std;
int main() {
string str = "123";
int a = stoi(str);
cout << a;
str = "123.44";
double b = stod(str);
cout << b;
return 0;
}
不仅有stoi和stod两种,相应的还有:
stof(string to flfloat)stold(string to long double)stol(string to long)stoll(string to long long)stoul(string to unsigned long)stoull(string to unsigned long long)
2.6 常见错误类型
平常刷题提交评测遇到错误时常见类型如下。
| 简写 | 全称 | 中文称谓 |
|---|---|---|
| OJ | Online Judge | 在线判题系统 |
| AC | Accepted | 通过 |
| WA | Wrong Answer | 答案错误 |
| TLE | Time Limit Exceed | 超时 |
| OLE | Output Limit Exceed | 超过输出限制 |
| MLE | Memory Limit Exceed | 超内存 |
| RE | Runtime Error | 运行时错误 |
| PE | Presentation Error | 格式错误 |
| CE | Compile Error | 无法编译 |
3 算法基础之常见模板
3.1 基础算法
- 快速排序
void quick_sort(int q[], int l, int r)
{
if (l >= r) return;
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
do i ++ ; while (q[i] < x);
do j -- ; while (q[j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
- 归并排序
void merge_sort(int q[], int l, int r)
{
if (l >= r) return;
int mid = l + r >> 1;
merge_sort(q, l, mid);
merge_sort(q, mid + 1, r);
int k = 0, i = l, j = mid + 1;
while (i <= mid && j <= r)
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ];
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
- 整数二分
bool check(int x) {/* ... */} // 检查x是否满足某种性质
// 区间[l, r]被划分成[l, mid]和[mid + 1, r]时使用:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid; // check()判断mid是否满足性质
else l = mid + 1;
}
return l;
}
// 区间[l, r]被划分成[l, mid - 1]和[mid, r]时使用:
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}
- 浮点数二分
bool check(double x) {/* ... */} // 检查x是否满足某种性质
double bsearch_3(double l, double r)
{
const double eps = 1e-6; // eps 表示精度,取决于题目对精度的要求
while (r - l > eps)
{
double mid = (l + r) / 2;
if (check(mid)) r = mid;
else l = mid;
}
return l;
}
- 高精度加法
// C = A + B, A >= 0, B >= 0
vector<int> add(vector<int> &A, vector<int> &B)
{
if (A.size() < B.size()) return add(B, A);
vector<int> C;
int t = 0;
for (int i = 0; i < A.size(); i ++ )
{
t += A[i];
if (i < B.size()) t += B[i];
C.push_back(t % 10);
t /= 10;
}
if (t) C.push_back(t);
return C;
}
- 高精度减法
// C = A - B, 满足A >= B, A >= 0, B >= 0
vector<int> sub(vector<int> &A, vector<int> &B)
{
vector<int> C;
for (int i = 0, t = 0; i < A.size(); i ++ )
{
t = A[i] - t;
if (i < B.size()) t -= B[i];
C.push_back((t + 10) % 10);
if (t < 0) t = 1;
else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
- 高精度乘低精度
// C = A * b, A >= 0, b >= 0
vector<int> mul(vector<int> &A, int b)
{
vector<int> C;
int t = 0;
for (int i = 0; i < A.size() || t; i ++ )
{
if (i < A.size()) t += A[i] * b;
C.push_back(t % 10);
t /= 10;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
- 高精度除以低精度
// A / b = C ... r, A >= 0, b > 0
vector<int> div(vector<int> &A, int b, int &r)
{
vector<int> C;
r = 0;
for (int i = A.size() - 1; i >= 0; i -- )
{
r = r * 10 + A[i];
C.push_back(r / b);
r %= b;
}
reverse(C.begin(), C.end());
while (C.size() > 1 && C.back() == 0) C.pop_back();
return C;
}
- 一维前缀和
S[i] = a[1] + a[2] + ... a[i]
a[l] + ... + a[r] = S[r] - S[l - 1]
- 二维前缀和
S[i, j] = 第i行j列格子左上部分所有元素的和
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
S[x2, y2] - S[x1 - 1, y2] - S[x2, y1 - 1] + S[x1 - 1, y1 - 1]
- 一维差分
给以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵中的所有元素加上c:
S[x1, y1] += c, S[x2 + 1, y1] -= c, S[x1, y2 + 1] -= c, S[x2 + 1, y2 + 1] += c
- 位运算
求n的第k位数字: n >> k & 1
返回n的最后一位1:lowbit(n) = n & -n
- 双指针算法
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ;
// 具体问题的逻辑
}
常见问题分类:
(1) 对于一个序列,用两个指针维护一段区间
(2) 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作
- 离散化
vector<int> alls; // 存储所有待离散化的值
sort(alls.begin(), alls.end()); // 将所有值排序
alls.erase(unique(alls.begin(), alls.end()), alls.end()); // 去掉重复元素
// 二分求出x对应的离散化的值
int find(int x) // 找到第一个大于等于x的位置
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; // 映射到1, 2, ...n
}
- 区间合并
// 将所有存在交集的区间合并
void merge(vector<PII> &segs)
{
vector<PII> res;
sort(segs.begin(), segs.end());
int st = -2e9, ed = -2e9;
for (auto seg : segs)
if (ed < seg.first)
{
if (st != -2e9) res.push_back({st, ed});
st = seg.first, ed = seg.second;
}
else ed = max(ed, seg.second);
if (st != -2e9) res.push_back({st, ed});
segs = res;
}
3.2 常见数据结构
- 单链表
// head存储链表头,e[]存储节点的值,ne[]存储节点的next指针,idx表示当前用到了哪个节点
int head, e[N], ne[N], idx;
// 初始化
void init()
{
head = -1;
idx = 0;
}
// 在链表头插入一个数a
void insert(int a)
{
e[idx] = a, ne[idx] = head, head = idx ++ ;
}
// 将头结点删除,需要保证头结点存在
void remove()
{
head = ne[head];
}
- 双链表
// e[]表示节点的值,l[]表示节点的左指针,r[]表示节点的右指针,idx表示当前用到了哪个节点
int e[N], l[N], r[N], idx;
// 初始化
void init()
{
//0是左端点,1是右端点
r[0] = 1, l[1] = 0;
idx = 2;
}
// 在节点a的右边插入一个数x
void insert(int a, int x)
{
e[idx] = x;
l[idx] = a, r[idx] = r[a];
l[r[a]] = idx, r[a] = idx ++ ;
}
// 删除节点a
void remove(int a)
{
l[r[a]] = l[a];
r[l[a]] = r[a];
}
- 栈
// tt表示栈顶
int stk[N], tt = 0;
// 向栈顶插入一个数
stk[ ++ tt] = x;
// 从栈顶弹出一个数
tt -- ;
// 栈顶的值
stk[tt];
// 判断栈是否为空
if (tt > 0)
{
}
- 队列
普通队列
// hh 表示队头,tt表示队尾
int q[N], hh = 0, tt = -1;
// 向队尾插入一个数
q[ ++ tt] = x;
// 从队头弹出一个数
hh ++ ;
// 队头的值
q[hh];
// 判断队列是否为空
if (hh <= tt)
{
}
循环队列
// hh 表示队头,tt表示队尾的后一个位置
int q[N], hh = 0, tt = 0;
// 向队尾插入一个数
q[tt ++ ] = x;
if (tt == N) tt = 0;
// 从队头弹出一个数
hh ++ ;
if (hh == N) hh = 0;
// 队头的值
q[hh];
// 判断队列是否为空
if (hh != tt)
{
}
- 单调栈
常见模型:找出每个数左边离它最近的比它大/小的数
int tt = 0;
for (int i = 1; i <= n; i ++ )
{
while (tt && check(stk[tt], i)) tt -- ;
stk[ ++ tt] = i;
}
- 单调队列
常见模型:找出滑动窗口中的最大值/最小值
int hh = 0, tt = -1;
for (int i = 0; i < n; i ++ )
{
while (hh <= tt && check_out(q[hh])) hh ++ ; // 判断队头是否滑出窗口
while (hh <= tt && check(q[tt], i)) tt -- ;
q[ ++ tt] = i;
}
- KMP
// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度
求模式串的Next数组:
for (int i = 2, j = 0; i <= m; i ++ )
{
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j ++ ;
ne[i] = j;
}
// 匹配
for (int i = 1, j = 0; i <= n; i ++ )
{
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j ++ ;
if (j == m)
{
j = ne[j];
// 匹配成功后的逻辑
}
}
- Trie树
int son[N][26], cnt[N], idx;
// 0号点既是根节点,又是空节点
// son[][]存储树中每个节点的子节点
// cnt[]存储以每个节点结尾的单词数量
// 插入一个字符串
void insert(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;
p = son[p][u];
}
cnt[p] ++ ;
}
// 查询字符串出现的次数
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
- 并查集
(1)朴素并查集:
int p[N]; //存储每个点的祖宗节点
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ ) p[i] = i;
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
(2)维护size的并查集:
int p[N], size[N];
//p[]存储每个点的祖宗节点, size[]只有祖宗节点的有意义,表示祖宗节点所在集合中的点的数量
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
size[i] = 1;
}
// 合并a和b所在的两个集合:
size[find(b)] += size[find(a)];
p[find(a)] = find(b);
(3)维护到祖宗节点距离的并查集:
int p[N], d[N];
//p[]存储每个点的祖宗节点, d[x]存储x到p[x]的距离
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x)
{
int u = find(p[x]);
d[x] += d[p[x]];
p[x] = u;
}
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ )
{
p[i] = i;
d[i] = 0;
}
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
d[find(a)] = distance; // 根据具体问题,初始化find(a)的偏移量
- 堆
// h[N]存储堆中的值, h[1]是堆顶,x的左儿子是2x, 右儿子是2x + 1
// ph[k]存储第k个插入的点在堆中的位置
// hp[k]存储堆中下标是k的点是第几个插入的
int h[N], ph[N], hp[N], size;
// 交换两个点,及其映射关系
void heap_swap(int a, int b)
{
swap(ph[hp[a]],ph[hp[b]]);
swap(hp[a], hp[b]);
swap(h[a], h[b]);
}
void down(int u)
{
int t = u;
if (u * 2 <= size && h[u * 2] < h[t]) t = u * 2;
if (u * 2 + 1 <= size && h[u * 2 + 1] < h[t]) t = u * 2 + 1;
if (u != t)
{
heap_swap(u, t);
down(t);
}
}
void up(int u)
{
while (u / 2 && h[u] < h[u / 2])
{
heap_swap(u, u / 2);
u >>= 1;
}
}
// O(n)建堆
for (int i = n / 2; i; i -- ) down(i);
- 一般哈希
(1) 拉链法
int h[N], e[N], ne[N], idx;
// 向哈希表中插入一个数
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
// 在哈希表中查询某个数是否存在
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
(2) 开放寻址法
int h[N];
// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != null && h[t] != x)
{
t ++ ;
if (t == N) t = 0;
}
return t;
}
- 字符串哈希
核心思想:将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
小技巧:取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
typedef unsigned long long ULL;
ULL h[N], p[N]; // h[k]存储字符串前k个字母的哈希值, p[k]存储 P^k mod 2^64
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i];
p[i] = p[i - 1] * P;
}
// 计算子串 str[l ~ r] 的哈希值
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
- STL简介
vector, 变长数组,倍增的思想
size() 返回元素个数
empty() 返回是否为空
clear() 清空
front()/back()
push_back()/pop_back()
begin()/end()
[]
支持比较运算,按字典序
pair<int, int>
first, 第一个元素
second, 第二个元素
支持比较运算,以first为第一关键字,以second为第二关键字(字典序)
string,字符串
size()/length() 返回字符串长度
empty()
clear()
substr(起始下标,(子串长度)) 返回子串
c_str() 返回字符串所在字符数组的起始地址
queue, 队列
size()
empty()
push() 向队尾插入一个元素
front() 返回队头元素
back() 返回队尾元素
pop() 弹出队头元素
priority_queue, 优先队列,默认是大根堆
size()
empty()
push() 插入一个元素
top() 返回堆顶元素
pop() 弹出堆顶元素
定义成小根堆的方式:priority_queue<int, vector<int>, greater<int>> q;
stack, 栈
size()
empty()
push() 向栈顶插入一个元素
top() 返回栈顶元素
pop() 弹出栈顶元素
deque, 双端队列
size()
empty()
clear()
front()/back()
push_back()/pop_back()
push_front()/pop_front()
begin()/end()
[]
set, map, multiset, multimap, 基于平衡二叉树(红黑树),动态维护有序序列
size()
empty()
clear()
begin()/end()
++, -- 返回前驱和后继,时间复杂度 O(logn)
set/multiset
insert() 插入一个数
find() 查找一个数
count() 返回某一个数的个数
erase()
(1) 输入是一个数x,删除所有x O(k + logn)
(2) 输入一个迭代器,删除这个迭代器
lower_bound()/upper_bound()
lower_bound(x) 返回大于等于x的最小的数的迭代器
upper_bound(x) 返回大于x的最小的数的迭代器
map/multimap
insert() 插入的数是一个pair
erase() 输入的参数是pair或者迭代器
find()
[] 注意multimap不支持此操作。 时间复杂度是 O(logn)
lower_bound()/upper_bound()
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
和上面类似,增删改查的时间复杂度是 O(1)
不支持 lower_bound()/upper_bound(), 迭代器的++,--
bitset, 圧位
bitset<10000> s;
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0
set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反
3.3 搜索与图论
- 树与图的存储
树是一种特殊的图,与图的存储方式相同。
对于无向图中的边ab,存储两条有向边a->b, b->a。
因此我们可以只考虑有向图的存储。
(1) 邻接矩阵:g[a][b]存储边a->b
(2) 邻接表:
// 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点
int h[N], e[N], ne[N], idx;
// 添加一条边a->b
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
// 初始化
idx = 0;
memset(h, -1, sizeof h);
- 树与图的遍历
时间复杂度$ O(n+m)O(n+m)$, $n$ 表示点数,$m$ 表示边数
(1) 深度优先遍历
int dfs(int u)
{
st[u] = true; // st[u] 表示点u已经被遍历过
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j]) dfs(j);
}
}
(2) 宽度优先遍历
queue<int> q;
st[1] = true; // 表示1号点已经被遍历过
q.push(1);
while (q.size())
{
int t = q.front();
q.pop();
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true; // 表示点j已经被遍历过
q.push(j);
}
}
}
- 拓扑排序
时间复杂度$ O(n+m)O(n+m)$, $n$ 表示点数,$m$ 表示边数
bool topsort()
{
int hh = 0, tt = -1;
// d[i] 存储点i的入度
for (int i = 1; i <= n; i ++ )
if (!d[i])
q[ ++ tt] = i;
while (hh <= tt)
{
int t = q[hh ++ ];
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (-- d[j] == 0)
q[ ++ tt] = j;
}
}
// 如果所有点都入队了,说明存在拓扑序列;否则不存在拓扑序列。
return tt == n - 1;
}
- 朴素dijkstra算法
时间复杂度$ O(n^2+m)$, $n$ 表示点数,$m$ 表示边数
int g[N][N]; // 存储每条边
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ )
{
int t = -1; // 在还未确定最短路的点中,寻找距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
- 堆优化版dijkstra
时间复杂度$ O(m\log n)$, $n$ 表示点数,$m$ 表示边数
typedef pair<int, int> PII;
int n; // 点的数量
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储所有点到1号点的距离
bool st[N]; // 存储每个点的最短距离是否已确定
// 求1号点到n号点的最短距离,如果不存在,则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
priority_queue<PII, vector<PII>, greater<PII>> heap;
heap.push({0, 1}); // first存储距离,second存储节点编号
while (heap.size())
{
auto t = heap.top();
heap.pop();
int ver = t.second, distance = t.first;
if (st[ver]) continue;
st[ver] = true;
for (int i = h[ver]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > distance + w[i])
{
dist[j] = distance + w[i];
heap.push({dist[j], j});
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
- Bellman-Ford算法
时间复杂度$ O(mn)$, $n$ 表示点数,$m$ 表示边数
int n, m; // n表示点数,m表示边数
int dist[N]; // dist[x]存储1到x的最短路距离
struct Edge // 边,a表示出点,b表示入点,w表示边的权重
{
int a, b, w;
}edges[M];
// 求1到n的最短路距离,如果无法从1走到n,则返回-1。
int bellman_ford()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
// 如果第n次迭代仍然会松弛三角不等式,就说明存在一条长度是n+1的最短路径,由抽屉原理,路径中至少存在两个相同的点,说明图中存在负权回路。
for (int i = 0; i < n; i ++ )
{
for (int j = 0; j < m; j ++ )
{
int a = edges[j].a, b = edges[j].b, w = edges[j].w;
if (dist[b] > dist[a] + w)
dist[b] = dist[a] + w;
}
}
if (dist[n] > 0x3f3f3f3f / 2) return -1;
return dist[n];
}
- spfa 算法(队列优化的Bellman-Ford算法)
时间复杂度 平均情况下 $O(m)O(m)$,最坏情况下$ O(nm)$,$n$ 表示点数,$m$ 表示边数
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N]; // 存储每个点到1号点的最短距离
bool st[N]; // 存储每个点是否在队列中
// 求1号点到n号点的最短路距离,如果从1号点无法走到n号点则返回-1
int spfa()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
queue<int> q;
q.push(1);
st[1] = true;
while (q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
if (!st[j]) // 如果队列中已存在j,则不需要将j重复插入
{
q.push(j);
st[j] = true;
}
}
}
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
- spfa判断图中是否存在负环
时间复杂度$ O(mn)$, $n$ 表示点数,$m$ 表示边数
int n; // 总点数
int h[N], w[N], e[N], ne[N], idx; // 邻接表存储所有边
int dist[N], cnt[N]; // dist[x]存储1号点到x的最短距离,cnt[x]存储1到x的最短路中经过的点数
bool st[N]; // 存储每个点是否在队列中
// 如果存在负环,则返回true,否则返回false。
bool spfa()
{
// 不需要初始化dist数组
// 原理:如果某条最短路径上有n个点(除了自己),那么加上自己之后一共有n+1个点,由抽屉原理一定有两个点相同,所以存在环。
queue<int> q;
for (int i = 1; i <= n; i ++ )
{
q.push(i);
st[i] = true;
}
while (q.size())
{
auto t = q.front();
q.pop();
st[t] = false;
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (dist[j] > dist[t] + w[i])
{
dist[j] = dist[t] + w[i];
cnt[j] = cnt[t] + 1;
if (cnt[j] >= n) return true; // 如果从1号点到x的最短路中包含至少n个点(不包括自己),则说明存在环
if (!st[j])
{
q.push(j);
st[j] = true;
}
}
}
}
return false;
}
- floyd算法
时间复杂度是 $O(n^3)$, $n$ 表示点数
初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ )
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
- 朴素版prim算法
时间复杂度是 $O(n2+m)$, $n$ 表示点数,$m$ 表示边数
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ )
{
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
}
return res;
}
- Kruskal算法
时间复杂度是 $O(m\log m)$, $n$ 表示点数,$m$ 表示边数
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
- 染色法判别二分图
时间复杂度是 $O(n+m)$, $n$ 表示点数,$m$ 表示边数
int n; // n表示点数
int h[N], e[M], ne[M], idx; // 邻接表存储图
int color[N]; // 表示每个点的颜色,-1表示未染色,0表示白色,1表示黑色
// 参数:u表示当前节点,c表示当前点的颜色
bool dfs(int u, int c)
{
color[u] = c;
for (int i = h[u]; i != -1; i = ne[i])
{
int j = e[i];
if (color[j] == -1)
{
if (!dfs(j, !c)) return false;
}
else if (color[j] == c) return false;
}
return true;
}
bool check()
{
memset(color, -1, sizeof color);
bool flag = true;
for (int i = 1; i <= n; i ++ )
if (color[i] == -1)
if (!dfs(i, 0))
{
flag = false;
break;
}
return flag;
}
- 匈牙利算法
时间复杂度是 $O(nm)$, $n$ 表示点数,$m$ 表示边数
int n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数
int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边
int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个
bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点
int res = 0;
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st);
if (find(i)) res ++ ;
}
3.4 数学知识
- 试除法判定质数
bool is_prime(int x)
{
if (x < 2) return false;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
return false;
return true;
}
- 试除法分解质因数
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
- 朴素筛法求素数
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (st[i]) continue;
primes[cnt ++ ] = i;
for (int j = i + i; j <= n; j += i)
st[j] = true;
}
}
- 线性筛法求素数
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
- 试除法求所有约数
vector<int> get_divisors(int x)
{
vector<int> res;
for (int i = 1; i <= x / i; i ++ )
if (x % i == 0)
{
res.push_back(i);
if (i != x / i) res.push_back(x / i);
}
sort(res.begin(), res.end());
return res;
}
- 约数个数和约数之和
如果 N = p1^c1 * p2^c2 * ... *pk^ck
约数个数: (c1 + 1) * (c2 + 1) * ... * (ck + 1)
约数之和: (p1^0 + p1^1 + ... + p1^c1) * ... * (pk^0 + pk^1 + ... + pk^ck)
- 欧几里得算法
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
- 求欧拉函数
int phi(int x)
{
int res = x;
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
res = res / i * (i - 1);
while (x % i == 0) x /= i;
}
if (x > 1) res = res / x * (x - 1);
return res;
}
- 筛法求欧拉函数
int primes[N], cnt; // primes[]存储所有素数
int euler[N]; // 存储每个数的欧拉函数
bool st[N]; // st[x]存储x是否被筛掉
void get_eulers(int n)
{
euler[1] = 1;
for (int i = 2; i <= n; i ++ )
{
if (!st[i])
{
primes[cnt ++ ] = i;
euler[i] = i - 1;
}
for (int j = 0; primes[j] <= n / i; j ++ )
{
int t = primes[j] * i;
st[t] = true;
if (i % primes[j] == 0)
{
euler[t] = euler[i] * primes[j];
break;
}
euler[t] = euler[i] * (primes[j] - 1);
}
}
}
- 快速幂
求 m^k mod p,时间复杂度 O(logk)。
int qmi(int m, int k, int p)
{
int res = 1 % p, t = m;
while (k)
{
if (k&1) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res;
}
- 扩展欧几里得算法
// 求x, y,使得ax + by = gcd(a, b)
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1; y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= (a/b) * x;
return d;
}
- 高斯消元
// a[N][N]是增广矩阵
int gauss()
{
int c, r;
for (c = 0, r = 0; c < n; c ++ )
{
int t = r;
for (int i = r; i < n; i ++ ) // 找到绝对值最大的行
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;
for (int i = c; i <= n; i ++ ) swap(a[t][i], a[r][i]); // 将绝对值最大的行换到最顶端
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c]; // 将当前行的首位变成1
for (int i = r + 1; i < n; i ++ ) // 用当前行将下面所有的列消成0
if (fabs(a[i][c]) > eps)
for (int j = n; j >= c; j -- )
a[i][j] -= a[r][j] * a[i][c];
r ++ ;
}
if (r < n)
{
for (int i = r; i < n; i ++ )
if (fabs(a[i][n]) > eps)
return 2; // 无解
return 1; // 有无穷多组解
}
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0; // 有唯一解
}
- 递归法求组合数
// c[a][b] 表示从a个苹果中选b个的方案数
for (int i = 0; i < N; i ++ )
for (int j = 0; j <= i; j ++ )
if (!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
- 通过预处理逆元的方式求组合数
首先预处理出所有阶乘取模的余数fact[N],以及所有阶乘取模的逆元infact[N]
如果取模的数是质数,可以用费马小定理求逆元
int qmi(int a, int k, int p) // 快速幂模板
{
int res = 1;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
// 预处理阶乘的余数和阶乘逆元的余数
fact[0] = infact[0] = 1;
for (int i = 1; i < N; i ++ )
{
fact[i] = (LL)fact[i - 1] * i % mod;
infact[i] = (LL)infact[i - 1] * qmi(i, mod - 2, mod) % mod;
}
- Lucas定理
若p是质数,则对于任意整数 1 <= m <= n,有:
C(n, m) = C(n % p, m % p) * C(n / p, m / p) (mod p)
int qmi(int a, int k, int p) // 快速幂模板
{
int res = 1 % p;
while (k)
{
if (k & 1) res = (LL)res * a % p;
a = (LL)a * a % p;
k >>= 1;
}
return res;
}
int C(int a, int b, int p) // 通过定理求组合数C(a, b)
{
if (a < b) return 0;
LL x = 1, y = 1; // x是分子,y是分母
for (int i = a, j = 1; j <= b; i --, j ++ )
{
x = (LL)x * i % p;
y = (LL) y * j % p;
}
return x * (LL)qmi(y, p - 2, p) % p;
}
int lucas(LL a, LL b, int p)
{
if (a < p && b < p) return C(a, b, p);
return (LL)C(a % p, b % p, p) * lucas(a / p, b / p, p) % p;
}
- 分解质因数法求组合数
当我们需要求出组合数的真实值,而非对某个数的余数时,分解质因数的方式比较好用:
1. 筛法求出范围内的所有质数
2. 通过 C(a, b) = a! / b! / (a - b)! 这个公式求出每个质因子的次数。 n! 中p的次数是 n / p + n / p^2 + n / p^3 + ...
3. 用高精度乘法将所有质因子相乘
int primes[N], cnt; // 存储所有质数
int sum[N]; // 存储每个质数的次数
bool st[N]; // 存储每个数是否已被筛掉
void get_primes(int n) // 线性筛法求素数
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int get(int n, int p) // 求n!中的次数
{
int res = 0;
while (n)
{
res += n / p;
n /= p;
}
return res;
}
vector<int> mul(vector<int> a, int b) // 高精度乘低精度模板
{
vector<int> c;
int t = 0;
for (int i = 0; i < a.size(); i ++ )
{
t += a[i] * b;
c.push_back(t % 10);
t /= 10;
}
while (t)
{
c.push_back(t % 10);
t /= 10;
}
return c;
}
get_primes(a); // 预处理范围内的所有质数
for (int i = 0; i < cnt; i ++ ) // 求每个质因数的次数
{
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p);
}
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i ++ ) // 用高精度乘法将所有质因子相乘
for (int j = 0; j < sum[i]; j ++ )
res = mul(res, primes[i]);
- 卡特兰数
给定n个0和n个1,它们按照某种顺序排成长度为2n的序列,满足任意前缀中0的个数都不少于1的个数的序列的数量为: Cat(n) = C(2n, n) / (n + 1)
- NIM游戏
给定N堆物品,第i堆物品有Ai个。两名玩家轮流行动,每次可以任选一堆,取走任意多个物品,可把一堆取光,但不能不取。取走最后一件物品者获胜。两人都采取最优策略,问先手是否必胜。
我们把这种游戏称为NIM博弈。把游戏过程中面临的状态称为局面。整局游戏第一个行动的称为先手,第二个行动的称为后手。若在某一局面下无论采取何种行动,都会输掉游戏,则称该局面必败。 所谓采取最优策略是指,若在某一局面下存在某种行动,使得行动后对面面临必败局面,则优先采取该行动。同时,这样的局面被称为必胜。我们讨论的博弈问题一般都只考虑理想情况,即两人均无失误,都采取最优策略行动时游戏的结果。 NIM博弈不存在平局,只有先手必胜和先手必败两种情况。
定理: NIM博弈先手必胜,当且仅当 A1 ^ A2 ^ … ^ An != 0
- 公平组合游戏ICG
若一个游戏满足:
- 由两名玩家交替行动;
- 在游戏进程的任意时刻,可以执行的合法行动与轮到哪名玩家无关;
- 不能行动的玩家判负; 则称该游戏为一个公平组合游戏。 NIM博弈属于公平组合游戏,但城建的棋类游戏,比如围棋,就不是公平组合游戏。因为围棋交战双方分别只能落黑子和白子,胜负判定也比较复杂,不满足条件2和条件3。
- 有向图游戏
给定一个有向无环图,图中有一个唯一的起点,在起点上放有一枚棋子。两名玩家交替地把这枚棋子沿有向边进行移动,每次可以移动一步,无法移动者判负。该游戏被称为有向图游戏。
任何一个公平组合游戏都可以转化为有向图游戏。具体方法是,把每个局面看成图中的一个节点,并且从每个局面向沿着合法行动能够到达的下一个局面连有向边。
- Mex运算
设$S$表示一个非负整数集合。定义$mex(S)$为求出不属于集合$S$的最小非负整数的运算,即: $mex(S) = min{x}$, $x$属于自然数,且$x$不属于$S$。
- SG函数
在有向图游戏中,对于每个节点$x$,设从$x$出发共有$k$条有向边,分别到达节点$y_1, y_2, …, y_k$,定义$SG(x)$为$x$的后继节点$y_1, y_2, …, y_k$ 的$SG$函数值构成的集合再执行$mex(S)$运算的结果,即: $SG(x) = mex({SG(y1), SG(y2), …, SG(yk)})$ 特别地,整个有向图游戏$G$的$SG$函数值被定义为有向图游戏起点$s$的$SG$函数值,即$SG(G) = SG(s)$。
- 有向图游戏的和
设$G_1, G_2, …, G_m$ 是$m$个有向图游戏。定义有向图游戏$G$,它的行动规则是任选某个有向图游戏$G_i$,并在$G_i$上行动一步。$G$被称为有向图游戏$G_1, G_2, …, G_m$的和。 有向图游戏的和的$SG$函数值等于它包含的各个子游戏$SG$函数值的异或和,即: SG(G) = SG(G1) ^ SG(G2) ^ … ^ SG(Gm)
定理
有向图游戏的某个局面必胜,当且仅当该局面对应节点的$SG$函数值大于0。 有向图游戏的某个局面必败,当且仅当该局面对应节点的$SG$函数值等于0。
4 算题说明
在进行高阶算法题前,至少得掌握这几种基本的算法思想:模拟、枚举、递归、分治、二分查找,要了解动态规划、贪心、回溯、深度优先搜索、宽度优先搜索的大致流程。
基础部分的书籍推荐《算法基础与在线实践》、进阶部分的书籍推荐《算法竞赛进阶指南》。
第二部分来自我结合网上资料的总结,第三部分的算法模板来自北大的某位大神,当我们逐渐刷题量变多时,可以整理出自己的模板,从而能够更加自如地应对大部分题。