基于两个开源库实现的语义SLAM。
本文首先用了一种非常简单粗暴的方法生成语义地图;先看看效果,之后逐渐改成了运行bag实时构建语义地图;这似乎也只能叫语义地图构建;不能叫语义slam因为语义信息并没有运行到前端匹配以及后段优化部分;
正确的思路应是语义信息可以帮助前端匹配部分添加一个约束帮助特征点的匹配增加系统的鲁棒性;这样在一些缺少文理的地形;即能利用相机能感知周围纹理的优势又能利用激光雷达感知距离的优势;后期逐渐完善
主要用到的两个github链接(感谢大佬):1.融合相机的aloam,https://github.com/TianXiaoRui/color_map_loam. 2.deeplabv3+:https://github.com/VainF/DeepLabV3Plus-Pytorch.
1、kitti数据集
1.1、下载
好多文章只给了一个kitti的主业但是当打开时并不知道下载哪一个;kitti的数据十分详细分类很多,可以查阅一些kitti的解释博客;官方在rawdata页面也给出了解释的论文;重要的是耐心的看一般英语水平问题不大;
http://www.cvlibs.net/publications/Geiger2013IJRR.pdf
第一次下载需要先注册一下问题不大;
https://pan.baidu.com/s/1h4k4o3VfnUZZm2nl21FyvA
提取码: cmm5
1.2、kitti数据集解释
下载后是4个文件夹(别的是我解压出来的);

calib是校准文件;包括
看一下kitti给出传感器位置图就能明白了

cam1是右侧灰度摄像机;cam1是右侧彩色摄像机;cam0是左侧灰度摄像机;cam1是左侧彩色摄像机;
现在再看三个标定文件就比较清楚了
cam_to_cam是四个相机之间的标定文件;包括相机的内参;
imu_velo是imu到雷达的标定文件;本文用不到
velo_to_cam是雷达到相机的标定文件;
雷达到相机的投影公式如下:
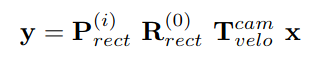

extract是原始数据;sync代表同步后的数据;
打开sync之后是这样的

image里存储着相机的图片;oxts里是imu和gnss的数据;velodyne里是雷达数据;
1.3、转成bag
在转换是extract和sync都可以转换成bag所有在转换时要确定好路径;自己能在kitti下载可以把标定文件放里面;
进入到这一个路径在extract和sync里都有;我们当然要用sync里的同步好的数据;打开终端
先安装kitti2bag

pip install kitti2bag
kitti2bag -t 2011_09_26 -r 0002 raw_synced
如果出现缺少pykitti的话尝试着换一个python环境;
我用conda创建了一个python3.6的环境就可以了;ubuntu18也自带py3.6;切换py2.7和py3.6的方式如下:
ubuntu切换python版本_Gone_float的博客-CSDN博客_ubuntu 切换python版本
过了几天在python3.6下又不行了这真奇怪;新建了一个py2.7安了一些包又行了;镇邪门;
https://www.csdn.net/tags/OtDaUg3sMTEwNTktYmxvZwO0O0OO0O0O.html
查看一下bag
rqt_bag kitti_2011_09_26_drive_0002_synced.bag
 选择一个话题右键选择view可以将其播放
选择一个话题右键选择view可以将其播放
2、融合相机的aloam
主要思路就是,将雷达点投影到相机从而获得相机像素坐标。将rgb值赋值给点云即可 2.1、对源码的一些更改
从github下载代码
https://github.com/TianXiaoRui/color_map_loam
我对他的代码做了几处更改
1、源代码使用的是cv::mat定义的矩阵运算,我总是编译不通过于是将其换成了Eigen
2、源代码似乎是从kitti的odom里下载的数据;只有R*T;我根据rawdata的论文将其改成了
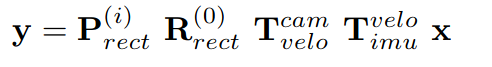
2.2、运行
打开一个终端
roscore
再打开一个终端
source devel/setup.bash
roslaunch aloam_velodyne aloam_velodyne_HDL_64.launch
再打开一个终端播放bag
rosbag play kitti_2011_09_26_drive_0002_synced.bag
效果

原图

也可以下载所有的bag;这个很大,任老自动驾驶定位教程给的链接; 3、deeplabv3+ 语义分割
kitti语义分割在如下的目录;但是由于此数据集只有200张训练集图片比较少;所有用于训练并不够;不过kitti的语义分割数据集是按照cityspace的数据集制作的所有可以用cityspaces的训练模型来预测kitti的图像;(效果也得却很好)

kitti数据集一共有19个类别;每个类别代表什么以及颜色如下:
labels = [
# name id trainId category catId hasInstances ignoreInEval color
Label( 'unlabeled' , 0 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , 'void' , 0 , False , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , 'void' , 0 , False , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , 'flat' , 1 , False , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , 'flat' , 1 , False , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , 'flat' , 1 , False , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , 'flat' , 1 , False , True , (230,150,140) ),
Label( 'building' , 11 , 2 , 'construction' , 2 , False , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , 'construction' , 2 , False , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , 'construction' , 2 , False , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , 'construction' , 2 , False , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , 'construction' , 2 , False , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , 'construction' , 2 , False , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , 'object' , 3 , False , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , 'object' , 3 , False , True , (153,153,153) ),
Label( 'traffic light' , 19 , 6 , 'object' , 3 , False , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , 'object' , 3 , False , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , 'nature' , 4 , False , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , 'nature' , 4 , False , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , 'sky' , 5 , False , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , 'human' , 6 , True , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , 'human' , 6 , True , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , 'vehicle' , 7 , True , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , 'vehicle' , 7 , True , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , 'vehicle' , 7 , True , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , 'vehicle' , 7 , True , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , 'vehicle' , 7 , True , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , 'vehicle' , 7 , True , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , 'vehicle' , 7 , True , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , 'vehicle' , 7 , True , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , 'vehicle' , 7 , False , True , ( 0, 0,142) ),
]
在deeplabv3+的github人家已经给出了训练好的cityspaces的模型下载下来直接对kitti进行预测就可以了 https://github.com/VainF/DeepLabV3Plus-Pytorch

3.1、预测
预测单个图像
python predict.py --input xxx.png --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt best_deeplabv3plus_mobilenet_cityscapes_os16.pth --save_val_results_to test_results
用全路径相对路径都可以
xxx.png: 想要预测的某张图片的路径
best_deeplabv3plus_mobilenet_cityscapes_os16.pth 权重文件的路径
test_results:预测结果的保存路径


预测某个文件夹下所有图像
python predict.py --input xxx --dataset cityscapes --model deeplabv3plus_mobilenet --ckpt
xxx为某个文件夹
预测好后将所有图片复制到替换原来的图像
/2011_09_26/2011_09_26_drive_0002_sync/image_02/data
再次生成bag文件
3.2、语义地图
重复以上建图过程
打开一个终端
roscore
再打开一个终端
source devel/setup.bash
roslaunch aloam_velodyne aloam_velodyne_HDL_64.launch
再打开一个终端播放bag
rosbag play kitti_2011_09_26_drive_sem.bag

4、正规方法
正规途径应该是将bag的image话题传送给deeplabv3+模型预测;预测好后在传给aloam进行建图;
deeplabv3+ 应用的是py3;但是运行aloam需要在py2;cvbridge也是ros自带的py2版本;所以需要用py3编译一个cvbridge放到环境变量让deeplabv3能找到它。但是在网上找了很多教程都能顺利编译我却怎么也编译不成功;所以才想出了这个笨方法;不过之后还是会按照正规方法进行实现。
过程如下:

4.1、从文件夹读取图像将分割结果实时发布到ros
deeplabv3+ predict修改;
主要修改后的可以直接通过 python predict.py运行或者通过如下方式运行
rosrun deeplab predict.py
deeplab是我的功能包名称
主要修改以下几处
4.1.1、将predict.py修改成python2版本
因为ros-melodic基于py2,然而deeplabv3+plus基于python3;有两种思路;
1、将一些ros的包编译成py3版本;并将其添加到环境变量;让建图程序运行时自动找到他们
2、使分割网络在py2下运行;这样两个程序就都可以在统一的python环境下运行了;
最终我还是选择了第二种方法;
修改方法很简单用anaconda创建一个py2环境在deeplab文件找到requirements.txt运行
pip install requirements.txt
按照github主业的运行方式运行一下;会发现一些问题主要是print在py2下一些用法不太兼容/注释调或者改成py2版本即可
在py2环境下可以运行后再继续修改方便我们将其添加到launch文件
将其调整为可以使用如下命令运行
rosrun deeplab predict.py
4.1.2、删除了get_parase()函数自己添加对应的参数
get_parase()函数主要是用来加载各种参数如下:还有一些其他参数根据get_parase()修改即可
decode_fn = Cityscapes.decode_target
gpu_id:只有一个gpu的话输入0即可(注意是字符串类型)
input:图像输入路径(可以是图片也可以是图片所在文件夹)
save_val_results_to:图像输出路径
ckpt==best_deeplabv3plus_mobilenet_cityscapes_os16.pth
并且添加了ros节点可以将分割好的话题发布到ros,和建图节点共同运行构建语义地图
#!/usr/bin/env python
from __future__ import print_function
from tkinter import image_names
import roslib
import sys
from torch.utils.data import dataset
from tqdm import tqdm
import network
import utils
import os
import random
import argparse
import numpy as np
from torch.utils import data
from datasets import VOCSegmentation, Cityscapes, cityscapes
from torchvision import transforms as T
from metrics import StreamSegMetrics
import cv2
import torch
import torch.nn as nn
from PIL import Image
import matplotlib
import matplotlib.pyplot as plt
from glob import glob
import roslib
#roslib.load_manifest('my_package')
import sys
import rospy
import cv2
from std_msgs.msg import String
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
# def get_argparser():
# parser = argparse.ArgumentParser()
# # Datset Options
# parser.add_argument("--input", type=str, required=True,
# help="path to a single image or image directory")
# parser.add_argument("--dataset", type=str, default='voc',
# choices=['voc', 'cityscapes'], help='Name of training set')
# # Deeplab Options
# available_models = sorted(name for name in network.modeling.__dict__ if name.islower() and \
# not (name.startswith("__") or name.startswith('_')) and callable(
# network.modeling.__dict__[name])
# )
# parser.add_argument("--model", type=str, default='deeplabv3plus_mobilenet',
# choices=available_models, help='model name')
# parser.add_argument("--separable_conv", action='store_true', default=False,
# help="apply separable conv to decoder and aspp")
# parser.add_argument("--output_stride", type=int, default=16, choices=[8, 16])
# # Train Options
# parser.add_argument("--save_val_results_to", default=None,
# help="save segmentation results to the specified dir")
# parser.add_argument("--crop_val", action='store_true', default=False,
# help='crop validation (default: False)')
# parser.add_argument("--val_batch_size", type=int, default=4,
# help='batch size for validation (default: 4)')
# parser.add_argument("--crop_size", type=int, default=513)
# parser.add_argument("--ckpt", default=None, type=str,
# help="resume from checkpoint")
# parser.add_argument("--gpu_id", type=str, default='0',
# help="GPU ID")
# return parser
if __name__ == '__main__':
print("somthing......")
rospy.init_node('kitti',anonymous=True)
print("somthing......")
bridge=CvBridge()
image_pub = rospy.Publisher("image_orioi",Image,queue_size=10)
image_sematic_pub=rospy.Publisher("sematic_image",Image,queue_size=10)
#opts = get_argparser().parse_args()
# if opts.dataset.lower() == 'voc':
# opts.num_classes = 21
# decode_fn = VOCSegmentation.decode_target
# elif opts.dataset.lower() == 'cityscapes':
# opts.num_classes = 19
# #1
# decode_fn = Cityscapes.decode_target
decode_fn = Cityscapes.decode_target
print("somthing2......")
#2 defalut=0
gpu_id="0"
#os.environ['CUDA_VISIBLE_DEVICES'] = opts.gpu_id
os.environ['CUDA_VISIBLE_DEVICES'] = gpu_id
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("Device: %s" % device)
# Setup dataloader
image_files = []
#3 input /home/du/work/study/ros/aloam_ws/src/deeplab/src/aachen/aachen_000000_000019_leftImg8bit.png
#input="/home/du/work/study/ros/aloam_ws/src/deeplab/src/aachen"
input="/home/du/work/study/ros/aloam_ws/cowtransfer/2011_09_26_drive_0002_sync/2011_09_26/2011_09_26_drive_0002_sync/image_03/data"
if os.path.isdir(input):
for file_name in os.listdir(input):
data_collect=input+'/'+file_name
image_files.append(data_collect)
#5 input /home/du/work/study/ros/aloam_ws/src/deeplab/src/aachen/aachen_000000_000019_leftImg8bit.png
elif os.path.isfile(input):
image_files.append(input)
# Set up model (all models are 'constructed at network.modeling)
#6 num_classes == 19 output_stride==16 defalut
model = network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=19, output_stride=16)
# if opts.separable_conv and 'plus' in "deeplabv3plus_mobilenet":
# network.convert_to_separable_conv(model.classifier)
print("somthing3......")
utils.set_bn_momentum(model.backbone, momentum=0.01)
print("somthing4......")
#7 ckpt==best_deeplabv3plus_mobilenet_cityscapes_os16.pth
if "/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth" is not None and os.path.isfile("/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth"):
# https://github.com/VainF/DeepLabV3Plus-Pytorch/issues/8#issuecomment-605601402, @PytaichukBohdan
checkpoint = torch.load("/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth", map_location=torch.device('cpu'))
model.load_state_dict(checkpoint["model_state"])
model = nn.DataParallel(model)
model.to(device)
print("Resume model from %s" % "/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth")
del checkpoint
else:
print("[!] Retrain")
model = nn.DataParallel(model)
model.to(device)
#denorm = utils.Denormalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # denormalization for ori images
# defalut == false
# if opts.crop_val:
# transform = T.Compose([
# T.Resize(opts.crop_size),
# T.CenterCrop(opts.crop_size),
# T.ToTensor(),
# T.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225]),
# ])
# else:
transform = T.Compose([
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# if opts.save_val_results_to is not None:
# #os.makedirs(opts.save_val_results_to, exist_ok=True)
# os.makedirs(opts.save_val_results_to)
with torch.no_grad():
model = model.eval()
for img_path in tqdm(image_files):
print("root is")
print(img_path)
ext = os.path.basename(img_path).split('.')[-1]
img_name = os.path.basename(img_path)[:-len(ext)-1]
print(img_name)
#img = Image.open(img_path).convert('RGB')
#opencv
img_bgr=cv2.imread(img_path)
#BGR->RGB
img = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
imgcv_msg=bridge.cv2_to_imgmsg(img,"bgr8")
image_pub.publish(imgcv_msg)
#cv->tensor
img = transform(img).unsqueeze(0) # To tensor of NCHW
img = img.to(device)
#predict
pred = model(img).max(1)[1].cpu().numpy()[0] # HW
colorized_preds = decode_fn(pred).astype('uint8')
#numpy->opencv
img_cv = cv2.cvtColor(colorized_preds,cv2.COLOR_RGB2BGR)
#opencv->rosmsg
img_msg=bridge.cv2_to_imgmsg(img_cv,"bgr8")
image_sematic_pub.publish(img_msg)
#print("publish success")
#numpy->Image
#colorized_preds = Image.fromarray(colorized_preds)
#colorized_preds.save(os.path.join(opts.save_val_results_to, img_name+'.png'))
cv2.imwrite(os.path.join("/home/du/work/study/ros/aloam_ws/src/deeplab/src/test_results", img_name+'.png'),img_cv)
print(os.path.join("/home/du/work/study/ros/aloam_ws/src/deeplab/src/test_results", img_name+'.png'))
# rospy.init_node('sematic_img', anonymous=True)
# try:
# rospy.spin()
# except KeyboardInterrupt:
# print("Shutting down")
4.1.3、运行
打开一个终端
roscore
再打开一个终端
打开anaconda的py2.7环境
conda activate py2.7
再source一下
source devel/setup.bash
运行程序
rosrun deeplab predict.py
现在可以打开你的结果保存文件夹看到语义分割好的图像都储存在那里面了
你可以选择单张图片或是一整个文件夹

4.2、运行bag直接进行语义分割和建图
在做slam过程中都要求实时建图;以上所说的方法都不行;一般是播放bag或者车上装传感器实时跑
所以我又对原来的predict.py代码进行了更改使他能从bag中读取图片然后实时分割并传给aloam节点进行点云语义投影
4.2.1、代码更改
整个代码只有100行左右,相比于上面的还要精简不少
先直接把代码放上来
#!/usr/bin/env python
from __future__ import print_function
from tkinter import image_names
import roslib
import sys
from torch.utils.data import dataset
from tqdm import tqdm
import network
import utils
import os
import random
import argparse
import numpy as np
from torch.utils import data
from datasets import VOCSegmentation, Cityscapes, cityscapes
from torchvision import transforms as T
from metrics import StreamSegMetrics
import cv2
import torch
import torch.nn as nn
from PIL import Image
import matplotlib
import matplotlib.pyplot as plt
from glob import glob
import roslib
#roslib.load_manifest('my_package')
import sys
import rospy
import cv2
from std_msgs.msg import String
from sensor_msgs.msg import Image
from cv_bridge import CvBridge, CvBridgeError
class sematicCloud:
def __init__(self) :
self.image_pub = rospy.Publisher("image_orioi",Image,queue_size=10)
self.sematic_img=rospy.Publisher("sematic_image",Image,queue_size=10)
self.image_sub = rospy.Subscriber("/kitti/camera_color_left/image_raw",Image,self.callback)
self.bridge = CvBridge()
self.decode_fn = Cityscapes.decode_target
self.gpu_id="0"
os.environ['CUDA_VISIBLE_DEVICES'] = self.gpu_id
self.device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model=network.modeling.__dict__["deeplabv3plus_mobilenet"](num_classes=19, output_stride=16)
self.checkpoint = torch.load("/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth", map_location=torch.device('cpu'))
self.model.load_state_dict(self.checkpoint["model_state"])
self.model = nn.DataParallel(self.model)
self.model=self.model.to(self.device).eval()
self.model.to(self.device)
print("Resume model from %s" % "/home/du/work/study/ros/aloam_ws/src/deeplab/src/best_deeplabv3plus_mobilenet_cityscapes_os16.pth")
del self.checkpoint
self.transform = T.Compose([
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
def callback(self,data):
print("hello world")
try:
#rosmsg->cv
img_bgr = self.bridge.imgmsg_to_cv2(data, "bgr8")
except CvBridgeError as e:
print(e)
img = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
imgcv_msg=self.bridge.cv2_to_imgmsg(img,"bgr8")
self.image_pub.publish(imgcv_msg)
#cv->tensor
img = self.transform(img).unsqueeze(0) # To tensor of NCHW
img = img.to(self.device)
#predict
pred = self.model(img).max(1)[1].cpu().numpy()[0] # HW
colorized_preds = self.decode_fn(pred).astype('uint8')
#numpy->opencv
img_cv = cv2.cvtColor(colorized_preds,cv2.COLOR_RGB2BGR)
#opencv->rosmsg
img_msg=self.bridge.cv2_to_imgmsg(img_cv,"bgr8")
img_msg.header.stamp=data.header.stamp
self.sematic_img.publish(img_msg)
# cv2.imwrite(os.path.join("/home/du/work/study/ros/aloam_ws/src/deeplab/src/test_results", img_name+'.png'),img_cv)
# print(os.path.join("/home/du/work/study/ros/aloam_ws/src/deeplab/src/test_results", img_name+'.png'))
def main(args):
sc = sematicCloud()
rospy.init_node('image_converter', anonymous=True)
try:
rospy.spin()
except KeyboardInterrupt:
print("Shutting down")
cv2.destroyAllWindows()
if __name__ == '__main__':
main(sys.argv)
将其写成了类的形式方便管理数据和数据处理的函数;
可以看到一些参数都再inint中进行了初始化很方便
callback函数负责语义分割部分;
修改完以上代码后可以直接运行
打开一个终端
roscore
再打开一个终端
打开anaconda的py2.7环境
conda activate py2.7
再source一下
source devel/setup.bash
运行程序
rosrun deeplab predict.py
再打开一个终端运行rviz
rosrun rviz rviz

再打开一个终端播放bag
rosbag play kitti_2011_09_26_drive_0002_synced.bag
就可以看到最终效果啦

4.2.2、结合aloam语义建图
上面的工作完成了再构建语义地图就比较简单了
只需更改两个地方
1、在H_64的launch文件中添加如下代码
<node pkg="deeplab" type="predict_copy.py" name="predict" output="screen" />
2、在map_building.cpp中将订阅图像的话题改成你自己的
ros::Subscriber subImage =nh.subscribe<sensor_msgs::Image>("sematic_image", 10,ImageHandler);
再运行就可以了
注:这种方法有gpu时可以实时cpu我也不太确定;感觉已经背离了slam实时重建的初衷
运行
打开一个终端
roscore
再打开一个终端
打开anaconda的py2.7环境
conda activate py2.7
再source一下
source devel/setup.bash
运行程序
roslaunch aloam_velodyne aloam_velodyne_HDL_64.launch
可以先在rviz中添加语义分割图像话题和原始图像话题后再跑bag
再打开一个终端播放bag
rosbag play kitti_2011_09_26_drive_0002_synced.bag
最终效果

跑完整kitti数据夹点云总是比里程计慢;这是一个很严重的问题
效果如下

5、车辆与行人检测
我们已经有了语义分割的图像,根据语义分割结果得到目标检测结果应该不难;
总体的思路是;根据语义分割图像画出被分割后汽车和人的最小外接矩形;提取出矩形的左上角坐标以及长和宽将其画在原图上即可;
流程如下:

其中cv.inRange的检测上下限可以通过下面的debug代码获得
# -*- coding: cp936 -*-
import cv2
import numpy as np
def nothing(x):
pass
img = cv2.imread('/home/du/work/study/opencv/Python_OpenCV_yuanma/Lesson31/yuyi.png')
cv2.namedWindow('hsv_debug')
cv2.createTrackbar('h_min','hsv_debug',0,180,nothing)
cv2.createTrackbar('s_min','hsv_debug',0,255,nothing)
cv2.createTrackbar('v_min','hsv_debug',0,255,nothing)
cv2.createTrackbar('h_max','hsv_debug',0,180,nothing)
cv2.createTrackbar('s_max','hsv_debug',0,255,nothing)
cv2.createTrackbar('v_max','hsv_debug',0,255,nothing)
hsv_img=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
while(1):
h_min=cv2.getTrackbarPos('h_min','hsv_debug')
s_min=cv2.getTrackbarPos('s_min','hsv_debug')
v_min=cv2.getTrackbarPos('v_min','hsv_debug')
h_max=cv2.getTrackbarPos('h_max','hsv_debug')
s_max=cv2.getTrackbarPos('s_max','hsv_debug')
v_max=cv2.getTrackbarPos('v_max','hsv_debug')
lower_green = np.array([h_min,s_min,v_min])
upper_green = np.array([h_max,s_max,v_max])
mask = cv2.inRange(hsv_img,lower_green,upper_green)
cv2.imshow('hsv_debug',mask)
k=cv2.waitKey(1)&0xFF
if k==27:
break
cv2.destroyAllWindows()
画出检测框代码如下
def dectImage(self,img_orioi,img_sematic):
img_orioi_copy=img_orioi
img_sematic_copy=img_sematic
hsv_image_sematic=cv2.cvtColor(img_sematic_copy,cv2.COLOR_BGR2HSV)
lower_blue=np.array([100,43,46])
upper_blue=np.array([124,255,153])
lower_red = np.array([0,122,120])
upper_red = np.array([10,255,255])
mask_red = cv2.inRange(hsv_image_sematic,lower_red,upper_red)
mask_red = cv2.medianBlur(mask_red, 5)
mask_red,contours_red,hierarchy = cv2.findContours(mask_red, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
mask_blue = cv2.inRange(hsv_image_sematic,lower_blue,upper_blue)
mask_blue = cv2.medianBlur(mask_blue, 5)
mask_blue,contours_blue,hierarchy = cv2.findContours(mask_blue, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
if contours_red:
for cnt in contours_red:
(x, y, w, h) = cv2.boundingRect(cnt)
cv2.rectangle(img_orioi_copy,(x,y),(x+w,y+h),(0,255,255),2)
cv2.putText(img_orioi_copy,"Person",(x,y),font,0.7,(0,255,0),2)
#cv->rosmsg
imgcv_dect=self.bridge.cv2_to_imgmsg(img_orioi_copy,"bgr8")
self.img_dect_pub.publish(imgcv_dect)
print("dect pub seccess")
elif contours_blue:
for cnt in contours_blue:
(x, y, w, h) = cv2.boundingRect(cnt)
cv2.rectangle(img_orioi_copy,(x,y),(x+w,y+h),(0,0,255),2)
cv2.putText(img_orioi_copy,"Car",(x,y),font,0.7,(0,0,255),2)
#cv->rosmsg
imgcv_dect=self.bridge.cv2_to_imgmsg(img_orioi_copy,"bgr8")
self.img_dect_pub.publish(imgcv_dect)
print("dect pub seccess")
else:
imgcv_dect=self.bridge.cv2_to_imgmsg(img_orioi_copy,"bgr8")
self.img_dect_pub.publish(imgcv_dect)
print("dect pub seccess")
运行方式与上面相同最终结果如下:
