ARM汇编入门笔记(下)。
ARM汇编入门笔记,包含常见的精简指令集编程汇总。
前言
ARM汇编的基础知识包括:
- Part 1:ARM汇编介绍
- Part 2:数据类型寄存器
- Part 3: ARM指令集
- Part 4: 内存相关指令:加载以及存储
- Part 5:重复性加载及存储
- Part 6: 分支和条件执行
- Part 7:栈以及函数
为了能跟着这个系列教程动手实践,你可以准备一个ARM的运行环境。如果你没有ARM设备(比如说树莓派或者手机),你可以通过QEMU来创建一个,教程在这(https://azeria-labs.com/emulate-raspberry-pi-with-qemu/)。如果你对于GDB调试的基础命令不熟悉的话,可以通过这个(https://azeria-labs.com/debugging-with-gdb-introduction/)学习。在这篇教程中,我们的核心关注点为32位的ARM,相关的例子在ARMv6下编译。
1 ARM汇编之连续存取
1.1 连续加载/存储
有时连续加载(存储)会显得更加高效。因为我们可以使用LDM(load multiple)以及STM(store multiple)。这些指令基于起始地址的不同,有不同的形式。下面是我们会在这一节用到的相关代码。在下文中会详细讲解。
.data
array_buff:
.word 0x00000000 /* array_buff[0] */
.word 0x00000000 /* array_buff[1] */
.word 0x00000000 /* array_buff[2]. 这一项存的是指向array_buff+8的指针 */
.word 0x00000000 /* array_buff[3] */
.word 0x00000000 /* array_buff[4] */
.text
.global main
main:
adr r0, words+12 /* words[3]的地址 -> r0 */
ldr r1, array_buff_bridge /* array_buff[0]的地址 -> r1 */
ldr r2, array_buff_bridge+4 /* array_buff[2]的地址 -> r2 */
ldm r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */
stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04 */
ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03, words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */
stmia r1, {r4-r6} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04; r6 -> array_buff[2] = 0x05 */
ldmib r0, {r4-r6} /* words[4] -> r4 = 0x04; words[5] -> r5 = 0x05; words[6] -> r6 = 0x06 */
stmib r1, {r4-r6} /* r4 -> array_buff[1] = 0x04; r5 -> array_buff[2] = 0x05; r6 -> array_buff[3] = 0x06 */
ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2] -> r5 = 0x02; words[1] -> r4 = 0x01 */
ldmdb r0, {r4-r6} /* words[2] -> r6 = 0x02; words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */
stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02; r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */
stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00; */
bx lr
words:
.word 0x00000000 /* words[0] */
.word 0x00000001 /* words[1] */
.word 0x00000002 /* words[2] */
.word 0x00000003 /* words[3] */
.word 0x00000004 /* words[4] */
.word 0x00000005 /* words[5] */
.word 0x00000006 /* words[6] */
array_buff_bridge:
.word array_buff /* array_buff的地址*/
.word array_buff+8 /* array_buff[2]的地址 */
在开始前,再深化一个概念,就是.word标识是对内存中长度为32位的数据块作引用。这对于理解代码中的偏移量很重要。所以程序中由.data段组成的数据,内存中会申请一个长度为5的4字节数组array_buff。我们的所有内存存储操作,都是针对这段内存中的数据段做读写的。而.text端包含着我们对内存操作的代码以及只读的两个标签,一个标签是含有七个元素的数组,另一个是为了链接.text段和.data段所存在的对于array_buff的引用。下面就开始一行行的分析了!
adr r0, words+12 /* words[3]的地址 -> r0 */
我们用ADR指令来获得words[3]的地址,并存到R0中。我们选了一个中间的位置是因为一会要做向前以及向后的操作。
gef> break _start
gef> run
gef> nexti
R0当前就存着words[3]的地址了,也就是0x80B8。也就是说,我们的数组word[0]的地址是:0x80AC(0x80B8-0XC)。
gef> x/7w 0x00080AC
0x80ac <words>: 0x00000000 0x00000001 0x00000002 0x00000003
0x80bc <words+16>: 0x00000004 0x00000005 0x00000006
接下来我们把R1和R2指向array_buff[0]以及array_buff[2]。在获取了这些指针后,我们就可以操作这个数组了。
ldr r1, array_buff_bridge /* array_buff[0]的地址 -> r1 */
ldr r2, array_buff_bridge+4 /* array_buff[2]的地址 -> r2 */
执行完上面这两条指令后,R1和R2的变化。
gef> info register r1 r2
r1 0x100d0 65744
r2 0x100d8 65752
下一条LDM指令从R0指向的内存中加载了两个字的数据。因为R0指向words[3]的起始处,所以words[3]的值赋给R4,words[4]的值赋给R5。
ldm r0, {r4,r5} /* words[3] -> r4 = 0x03; words[4] -> r5 = 0x04 */
所以我们用一条指令加载了两个数据块,并且放到了R4和R5中。
gef> info registers r4 r5
r4 0x3 3
r5 0x4 4
看上去不错,再来看看STM指令。STM指令将R4与R5中的值0x3和0x4存储到R1指向的内存中。这里R1指向的是array_buff[0],也就是说 array_buff[0] = 0x00000003以及array_buff[1] = 0x00000004。如不特定指定,LDM与STM指令操作的最小单位都是一个字(四字节)。
stm r1, {r4,r5} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04 */
值0x3与0x4被存储到了R1指向的地方0x100D0以及0x100D4。
gef> x/2w 0x000100D0
0x100d0 <array_buff>: 0x00000003 0x00000004
之前说过LDM和STM有多种形式。不同形式的扩展字符和含义都不同:
- IA(increase after)
- IB(increase before)
- DA(decrease after)
- DB(decrease before)
这些扩展划分的主要依据是,作为源地址或者目的地址的指针是在访问内存前增减,还是访问内存后增减。以及,LDM与LDMIA功能相同,都是在加载操作完成后访问对地址增加的。通过这种方式,我们可以序列化的向前或者向后从一个指针指向的内存加载数据到寄存器,或者存放数据到内存。如下示意代码 。
ldmia r0, {r4-r6} /* words[3] -> r4 = 0x03, words[4] -> r5 = 0x04; words[5] -> r6 = 0x05; */
stmia r1, {r4-r6} /* r4 -> array_buff[0] = 0x03; r5 -> array_buff[1] = 0x04; r6 -> array_buff[2] = 0x05 */
在执行完这两条代码后,R4到R6寄存器所访问的内存地址以及存取的值是0x000100D0,0x000100D4,以及0x000100D8,值对应是 0x3,0x4,以及0x5。
gef> info registers r4 r5 r6
r4 0x3 3
r5 0x4 4
r6 0x5 5
gef> x/3w 0x000100D0
0x100d0 <array_buff>: 0x00000003 0x00000004 0x00000005
而LDMIB指令会首先对指向的地址先加4,然后再加载数据到寄存器中。所以第一次加载的时候也会对指针加4,所以存入寄存器的是0X4(words[4])而不是0x3(words[3])。
dmib r0, {r4-r6} /* words[4] -> r4 = 0x04; words[5] -> r5 = 0x05; words[6] -> r6 = 0x06 */
stmib r1, {r4-r6} /* r4 -> array_buff[1] = 0x04; r5 -> array_buff[2] = 0x05; r6 -> array_buff[3] = 0x06 */
执行后的调试示意:
gef> x/3w 0x100D4
0x100d4 <array_buff+4>: 0x00000004 0x00000005 0x00000006
gef> info register r4 r5 r6
r4 0x4 4
r5 0x5 5
r6 0x6 6
当用LDMDA指令时,执行的就是反向操作了。R0指向words[3],当加载数据时数据的加载方向变成加载words[3],words[2],words[1]的值到R6,R5,R4中。这种加载流程发生的原因是我们LDM指令的后缀是DA,也就是在加载操作完成后,会将指针做递减的操作。注意在做减法模式下的寄存器的操作是反向的,这么设定的原因为了保持让编号大的寄存器访问高地址的内存的原则。
多次加载,后置减法:
ldmda r0, {r4-r6} /* words[3] -> r6 = 0x03; words[2] -> r5 = 0x02; words[1] -> r4 = 0x01 */
执行之后,R4-R6的值:
gef> info register r4 r5 r6
r4 0x1 1
r5 0x2 2
r6 0x3 3
多次加载,前置减法:
ldmdb r0, {r4-r6} /* words[2] -> r6 = 0x02; words[1] -> r5 = 0x01; words[0] -> r4 = 0x00 */
执行之后,R4-R6的值:
gef> info register r4 r5 r6
r4 0x0 0
r5 0x1 1
r6 0x2 2
多次存储,后置减法:
stmda r2, {r4-r6} /* r6 -> array_buff[2] = 0x02; r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00 */
执行之后,array_buff[2],array_buff[1],以及array_buff[0]的值:
gef> x/3w 0x100D0
0x100d0 <array_buff>: 0x00000000 0x00000001 0x00000002
多次存储,前置减法:
stmdb r2, {r4-r5} /* r5 -> array_buff[1] = 0x01; r4 -> array_buff[0] = 0x00; */
执行之后,array_buff[1],以及array_buff[0]的值:
gef> x/2w 0x100D0
0x100d0 <array_buff>: 0x00000000 0x00000001
2. PUSH和POP
在内存中存在一块进程相关的区域叫做栈。栈指针寄存器SP在正常情形下指向这篇区域。应用经常通过栈做临时的数据存储。X86使用PUSH和POP来访问存取栈上数据。在ARM中我们也可以用这两条指令:
当PUSH压栈时,会发生以下事情:
- SP值减4。
-
存放信息到SP指向的位置。 当POP出栈时,会发生以下事情:
- 数据从SP指向位置被加载
- SP值加4。 下面是我们使用PUSH/POP以及LDMIA/STMDB命令示例: ``` .text .global _start
_start: mov r0, #3 mov r1, #4 push {r0, r1} pop {r2, r3} stmdb sp!, {r0, r1} ldmia sp!, {r4, r5} bkpt
让我们来看看这段汇编的反汇编:
azeria@labs:~$ as pushpop.s -o pushpop.o azeria@labs:~$ ld pushpop.o -o pushpop azeria@labs:~$ objdump -D pushpop pushpop: file format elf32-littlearm
Disassembly of section .text:
00008054 <_start>: 8054: e3a00003 mov r0, #3 8058: e3a01004 mov r1, #4 805c: e92d0003 push {r0, r1} 8060: e8bd000c pop {r2, r3} 8064: e92d0003 push {r0, r1} 8068: e8bd0030 pop {r4, r5} 806c: e1200070 bkpt 0x0000
可以看到,我们的LDMIA以及STMDB指令被编译器换为了PUSH和POP。因为PUSH和STMDB sp!是等效的。同样的还有POP和LDMIA sp!。让我们在GDB里面跑一下上面那段汇编代码。
gef> break _start gef> run gef> nexti 2 […] gef> x/w $sp 0xbefff7e0: 0x00000001
在连续执行完前两条指令后,我们来看看SP,下一条PUSH指令会将其减8,并将R1和R0的值按序存放到栈上。
gef> nexti […] —– Stack —– 0xbefff7d8|+0x00: 0x3 <- $sp 0xbefff7dc|+0x04: 0x4 0xbefff7e0|+0x08: 0x1 […] gef> x/w $sp 0xbefff7d8: 0x00000003
再之后,这两个值被出栈,按序存到寄存器R2和R3中,之后SP加8。
gef> nexti gef> info register r2 r3 r2 0x3 3 r3 0x4 4 gef> x/w $sp 0xbefff7e0: 0x00000001
## 2 ARM汇编之条件执行与分支
### 2.1 条件执行
在之前讨论CPSR寄存器那部分时,我们大概提了一下条件执行这个词。条件执行用来控制程序执行跳转,或者满足条件下的特定指令的执行。相关条件在CPSR寄存器中描述。寄存器中的比特位的变化决定着不同的条件。比如说当我们比较两个数是否相同时,我们使用的Zero比特位(Z=1),因为这种情况下发生的运算是a-b=0。在这种情况下我们就满足了EQual的条件。如果第一个数更大些,我们就满足了更大的条件Grater Than或者相反的较小Lower Than。条件缩写都是英文首字母缩写,比如小于等于Lower Than(LE),大于等于Greater Equal(GE)等。
下面列表是各个条件的含义以及其检测的状态位(条件指令都是其英文含义的缩写,为了便于记忆不翻译了):
下面列表是各个条件的含义以及其检测的状态位:
| Condition Code | Meaning (for cmp or subs) | Status of Flags |
|----------------|----------------------------------------|-------------------|
| EQ | Equal | Z==1 |
| NE | Not Equal | Z==0 |
| GT | Signed Greater Than | (Z==0) && (N==V) |
| LT | Signed Less Than | N!=V |
| GE | Signed Greater Than or Equal | N==V |
| LE | Signed Less Than or Equal | (Z==1) || (N!=V) |
| CS or HS | Unsigned Higher or Same (or Carry Set) | C==1 |
| CC or LO | Unsigned Lower (or Carry Clear) | C==0 |
| MI | Negative (or Minus) | N==1 |
| PL | Positive (or Plus) | N==0 |
| AL | Always executed | – |
| NV | Never executed | – |
| VS | Signed Overflow | V==1 |
| VC | No signed Overflow | V==0 |
| HI | Unsigned Higher | (C==1) && (Z==0) |
| LS | Unsigned Lower or same | (C==0) || (Z==0) |
我们使用如下代码来实践条件执行相加指令:
.global main
main: mov r0, #2 /* 初始化值 / cmp r0, #3 / 将R0和3相比做差,负数产生则N位置1 / addlt r0, r0, #1 / 如果小于等于3,则R0加一 / cmp r0, #3 / 将R0和3相比做差,零结果产生则Z位置一,N位置恢复为0 / addlt r0, r0, #1 / 如果小于等于3,则R0加一R0 IF it was determined that it is smaller (lower than) number 3 */ bx lr
上面代码段中的第一条`CMP`指令将N位置一同时也就指明了R0比3小。之后`ADDLT`指令在LT条件下执行,对应到CPSR寄存器的情况时V与N比特位不能相同。在执行第二条`CMP`前,R0=3。所以第二条置了Z位而消除了N位。所以`ADDLT`不会执行R0也不会被修改,最终程序结果是3。
### 2.2 Thumb模式中的条件执行
在指令集那篇文章中我们谈到了不同的指令集,对于Thumb中,其实也有条件执的(Thumb-2中有)。有些ARM处理器版本支持IT指令,允许在Thumb模式下条件执行最多四条指令。
相关引用:http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0552a/BABIJDIC.html
指令格式:Syntax: IT{x{y{z}}} cond
- cond 代表在IT指令后第一条条件执行执行指令的需要满足的条件。
- x 代表着第二条条件执行指令要满足的条件逻辑相同还是相反。
- y 代表着第三条条件执行指令要满足的条件逻辑相同还是相反。
- z 代表着第四条条件执行指令要满足的条件逻辑相同还是相反。
IT指令的含义是“IF-Then-(Else)”,跟这个形式类似的还有:
- IT,If-Then,接下来的一条指令条件执行。
- ITT,If-Then-Then,接下来的两条指令条件执行。
- ITE,If-Then-Else,接下来的两条指令条件执行。
- ITTE,If-Then-Then-Else,接下来的三条指令条件执行。
- ITTEE,If-Then-Then-Else-Else,接下来的四条指令条件执行。
在IT块中的每一条条件执行指令必须是相同逻辑条件或者相反逻辑条件。比如说ITE指令,第一条和第二条指令必须使用相同的条件,而第三条必须是与前两条逻辑上相反的条件。这有一些ARM reference上的例子:
ITTE NE ; 后三条指令条件执行 ANDNE R0, R0, R1 ; ANDNE不更新条件执行相关flags ADDSNE R2, R2, #1 ; ADDSNE更新条件执行相关flags MOVEQ R2, R3 ; 条件执行的move
ITE GT ; 后两条指令条件执行 ADDGT R1, R0, #55 ; GT条件满足时执行加 ADDLE R1, R0, #48 ; GT条件不满足时执行加
ITTEE EQ ; 后两条指令条件执行 MOVEQ R0, R1 ; 条件执行MOV ADDEQ R2, R2, #10 ; 条件执行ADD ANDNE R3, R3, #1 ; 条件执行AND BNE.W dloop ; 分支指令只能在IT块的最后一条指令中使用
错误的格式:
IT NE ; 下一条指令条件执行 ADD R0, R0, R1 ; 格式错误:没有条件指令
下图是条件指令后缀含义以及他们的逻辑相反指令:
条件指令:
| EQ | Equal |
|----------------|---------------------------------------|
| HS(or CS) | Unsigned higher or same(or carry set) |
| MI | Negative |
| VS | Signed Overflow |
| HI | Unsigned Higher |
| GE | Signed Greater Than or Equal |
| GT | Signed Greater Than |
| AL(or omitted) | Always Executed |
逻辑取反:
| NE | Not Equal |
|-----------|---------------------------------|
| LO(or CC) | Unsigned lower(or carry clear) |
| PL | Positive or Zero |
| VC | No Signed Overflow |
| LS | Unsigned Lower or Same |
| LT | Signed Less Than |
| LE | Signed Less Than or Equal |
让我们试试下面这段代码:
.syntax unified @ 这很重要! .text .global _start
_start: .code 32 add r3, pc, #1 @ R3=pc+1 bx r3 @ 分支跳转到R3并且切换到Thumb模式下由于最低比特位为1
.code 16 @ Thumb模式
cmp r0, #10
ite eq @ if R0 == 10
addeq r1, #2 @ then R1 = R1 + 2
addne r1, #3 @ else R1 = R1 + 3
bkpt ```
.code32是指代码在ARM模式下执行。第一条机器码将PC地址加一并且送给了R3。在之后的跳转中就切换到了Thumb模式。这也是bx与b指令的区别,前者会切换状态而后者不会。、
.code16是在Thumb模式下执行的代码。这段代码中的条件执行前提是R0等于10。ADDEQ指令代表了如果条件满足,那么就执行R1=R1+2,ADDNE代表了不满足时候的情况。
2.3 分支指令
分支指令(也叫分支跳转)允许我们在代码中跳转到别的段。当我们需要跳到一些函数上执行或者跳过一些代码块时很有用。这部分的最佳例子就是条件跳转IF以及循环。先来看看IF分支。
.global main
main:
mov r1, #2 /* 初始化 a */
mov r2, #3 /* 初始化 b */
cmp r1, r2 /* 比较谁更大些 */
blt r1_lower /* 如果R2更大跳转到r1_lower */
mov r0, r1 /* 如果分支跳转没有发生,将R1的值放到到R0 */
b end /* 跳转到结束 */
r1_lower:
mov r0, r2 /* 将R2的值放到R0 */
b end /* 跳转到结束 */
end:
bx lr /* THE END */
上面的汇编代码的含义就是找到较大的数,类似的C伪代码是这样的:
int main() {
int max = 0;
int a = 2;
int b = 3;
if(a < b) {
max = b;
}
else {
max = a;
}
return max;
}
再来看看循环中的条件分支:
.global main
main:
mov r0, #0 /* 初始化 a */
loop:
cmp r0, #4 /* 检查 a==4 */
beq end /* 如果是则结束 */
add r0, r0, #1 /* 如果不是则加1 */
b loop /* 重复循环 */
end:
bx lr /* THE END */
对应的C伪代码长这样子:
int main() {
int a = 0;
while(a < 4) {
a= a+1;
}
return a;
}
2.4 B/BX/BLX
有三种类型的分支指令:
- Branch(B)
- 简单的跳转到一个函数
- Branch link(BL)
- 将下一条指令的入口(PC+4)保存到LR,跳转到函数
- Branch exchange(BX) 以及 Branch link exchange(BLX)
- 与B/BL相同,外加执行模式切换(ARM与Thumb)
- 需要寄存器类型作为第一操作数:BX/BLX reg BX/BLX指令被用来从ARM模式切换到Thumb模式。
.text
.global _start
_start:
.code 32 @ ARM模式
add r2, pc, #1 @ PC+1放到R2
bx r2 @ 分支切换到R2
.code 16 @ Thumb模式
mov r0, #1
上面的代码将当前的PC值加1存放到了R2中(此时PC指向其后两条指令的偏移处),通过BX跳转到了寄存器指向的位置,由于最低有效位为1,所以切换到Thumb模式执行。下面GDB调试的动图说明了这一切。

2.5 条件分支指令
条件分支指令是指在满足某种特定条件下的跳转指令。指令模式是跳转指令后加上条件后缀。我们用BEQ来举例吧。下面这段汇编代码对一些值做了操作,然后依据比较结果进行条件分支跳转。
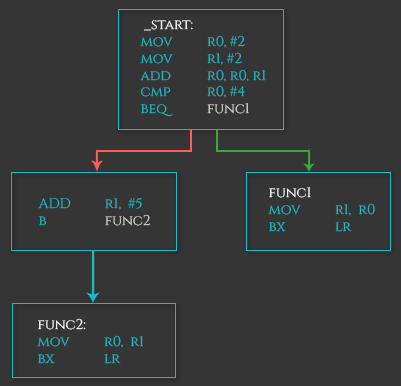
对应汇编代码如下:
.text
.global _start
_start:
mov r0, #2
mov r1, #2
add r0, r0, r1
cmp r0, #4
beq func1
add r1, #5
b func2
func1:
mov r1, r0
bx lr
func2:
mov r0, r1
bx lr
3 ARM汇编之栈与函数
在这部分我们将研究一篇独特的内存区域叫做栈,讲解栈的目的以及相关操作。除此之外,我们还会研究ARM架构中函数的调用约定。
3.1 栈
一般来说,栈是一片在程序/进程中的内存区域。这部分内存是在进程创建的时候被创建的。我们利用栈来存储一些临时数据比如说函数的局部变量,环境变量等。在之前的文章中,我们讲了操作栈的相关指令PUSH和POP。
在我们开始之前,还是了解一下栈的相关知识以及其实现方式吧。首先谈谈栈的增长,即当我们把32位的数据放到栈上时候它的变化。栈可以向上增长(当栈的实现是负向增长时),或者向下增长(当栈的实现是正向增长时)。具体的关于下一个32位的数据被放到哪里是由栈指针来决定的,更精确的说是由SP寄存器决定。不过这里面所指向的位置,可能是当前(也就是上一次)存储的数据,也可能是下一次存储时的位置。如果SP当前指向上一次存放的数据在栈中的位置(满栈实现),SP将会递减(降序栈)或者递增(升序栈),然后再对指向的内容进行操作。而如果SP指向的是下一次要操作的数据的空闲位置(空栈实现),数据会先被存放,而后SP会被递减(降序栈)或递增(升序栈)。
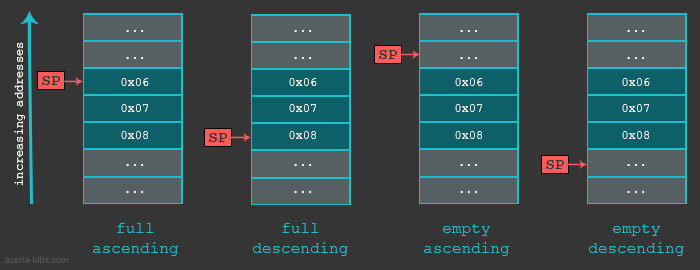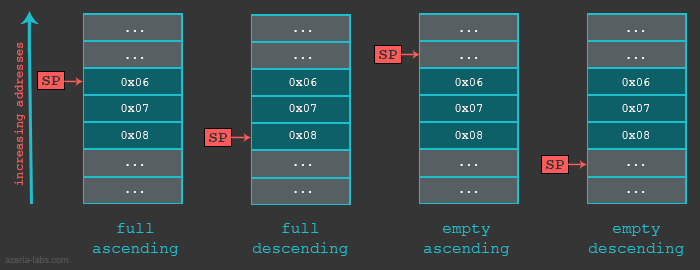
不同的栈实现,可以用不同情形下的多次存取指令来表示(这里很绕…):
| 栈类型 | 压栈(存储) | 弹栈(加载) |
|---|---|---|
| 满栈降序(FD,Full descending) | STMFD(等价于STMDB,操作之前递减) | LDMFD(等价于LDM,操作之后递加) |
| 满栈增序(FA,Full ascending) | STMFA(等价于STMIB,操作之前递加) | LDMFA(等价于LDMDA,操作之后递减) |
| 空栈降序(ED,Empty descending) | STMED(等价于STMDA,操作之后递减) | LDMED(等价于LDMIB,操作之前递加) |
| 空栈增序(EA,Empty ascending) | STMEA(等价于STM,操作之后递加) | LDMEA(等价于LDMDB,操作之前递减) |
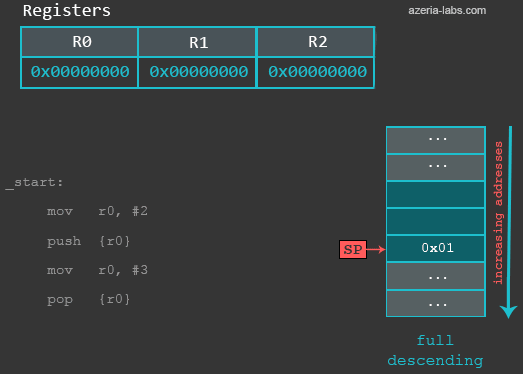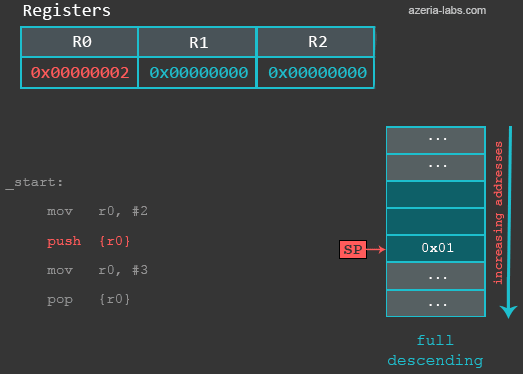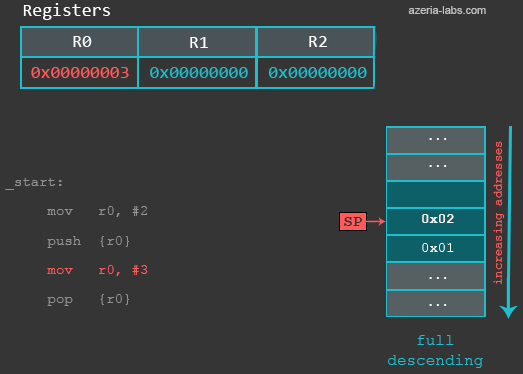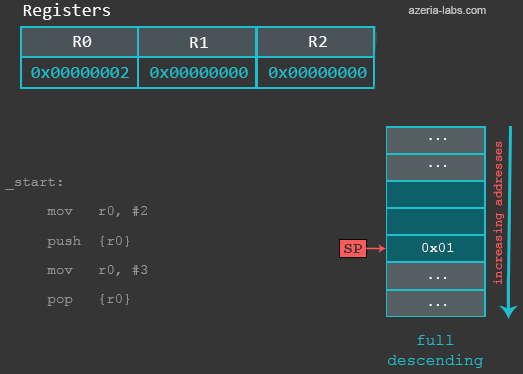
我们的例子中,使用的是满栈降序的栈实现。让我们看一个栈相关的例子。
/* azeria@labs:~$ as stack.s -o stack.o && gcc stack.o -o stack && gdb stack */
.global main
main:
mov r0, #2 /* 设置R0 */
push {r0} /* 将R0存在栈上 */
mov r0, #3 /* 修改R0 */
pop {r0} /* 恢复R0为初始值 */
bx lr /* 程序结束 */
在一开始,栈指针指向地址0xbefff6f8,代表着上一次入栈数据的位置。可以看到当前位置存储了一些值。
gef> x/1x $sp
0xbefff6f8: 0xb6fc7000
在执行完第一条指令MOV后,栈没有改变。在只执行完下一条PUSH指令后,首先SP的值会被减4字节。之后存储在R0中的值会被存放到SP指向的位置中。现在我们在看看SP指向的位置以及其中的值。
gef> x/x $sp
0xbefff6f4: 0x00000002
在执行完第一条指令MOV后,栈没有改变。在只执行完下一条PUSH指令后,首先SP的值会被减4字节。之后存储在R0中的值会被存放到SP指向的位置中。现在我们在看看SP指向的位置以及其中的值。
gef> x/x $sp
0xbefff6f4: 0x00000002
之后的指令将R0的值修改为3。然后我们执行POP指令将SP中的值存放到R0中,并且将SP的值加4,指向当前栈顶存放数据的位置。z最终R0的值是2。
gef> info registers r0
r0 0x2 2
(下面的动图展示了低地址在顶部的栈的变化情况)
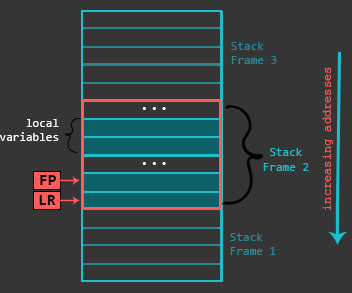
栈被用来存储局部变量,之前的寄存器状态。为了统一管理,函数使用了栈帧这个概念,栈帧是在栈内用于存储函数相关数据的特定区域。栈帧在函数开始时被创建。栈帧指针(FP)指向栈帧的底部元素,栈帧指针确定后,会在栈上申请栈帧所属的缓冲区。栈帧(从它的底部算起)一般包含着返回地址(之前说的LR),上一层函数的栈帧指针,以及任何需要被保存的寄存器,函数参数(当函数需要4个以上参数时),局部变量等。虽然栈帧包含着很多数据,但是这其中不少类型我们之前已经了解过了。最后,栈帧在函数结束时被销毁。
下图是关于栈帧的在栈中的位置的抽象描述(默认栈,满栈降序):
来一个例子来更具体的了解下栈帧吧:
/* azeria@labs:~$ gcc func.c -o func && gdb func */
int main()
{
int res = 0;
int a = 1;
int b = 2;
res = max(a, b);
return res;
}
int max(int a,int b)
{
do_nothing();
if(a<b)
{
return b;
}
else
{
return a;
}
}
int do_nothing()
{
return 0;
}
在下面的截图中我们可以看到GDB中栈帧的相关信息:
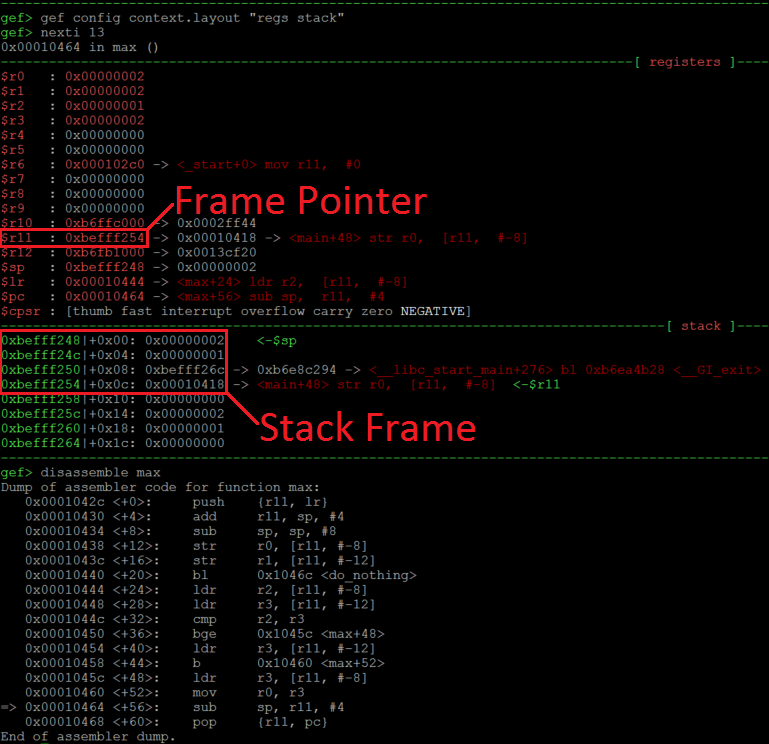
可以看到上面的图片中我们即将离开函数max(最下面的反汇编中可以看到)。在此时,FP(R11)寄存器指向的0xbefff254就是当前栈帧的底部。这个地址对应的栈上(绿色地址区域)位置存储着0x00010418这个返回地址(LR)。再往上看4字节是0xbefff26c。可以看到这个值是上层函数的栈帧指针。在0xbefff24c和0xbefff248的0x1和0x2是函数max执行时产生的局部变量。所以栈帧包含着我们之前说过的LR,FP以及两个局部变量。
3.2 函数
在开始学习ARM下的函数前,我们需要先明白一个函数的结构:
- 序言准备(Prologue)
- 函数体
- 结束收尾(Epilogue)
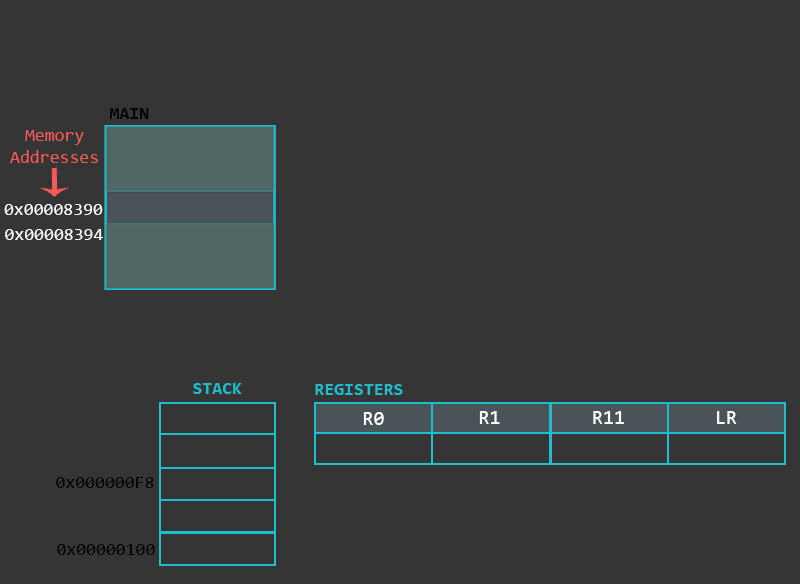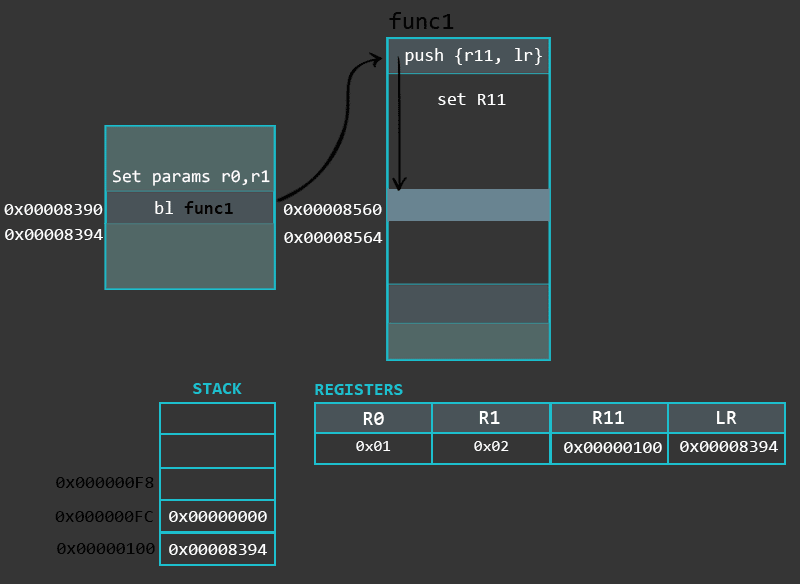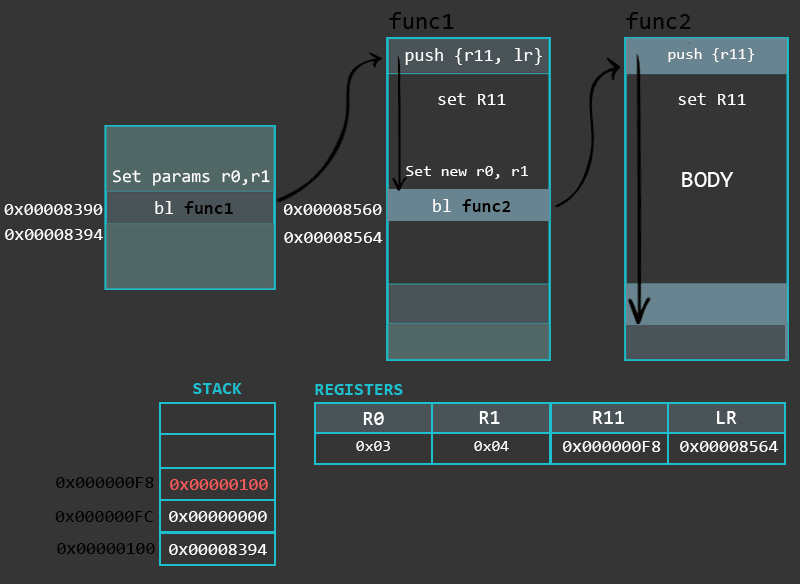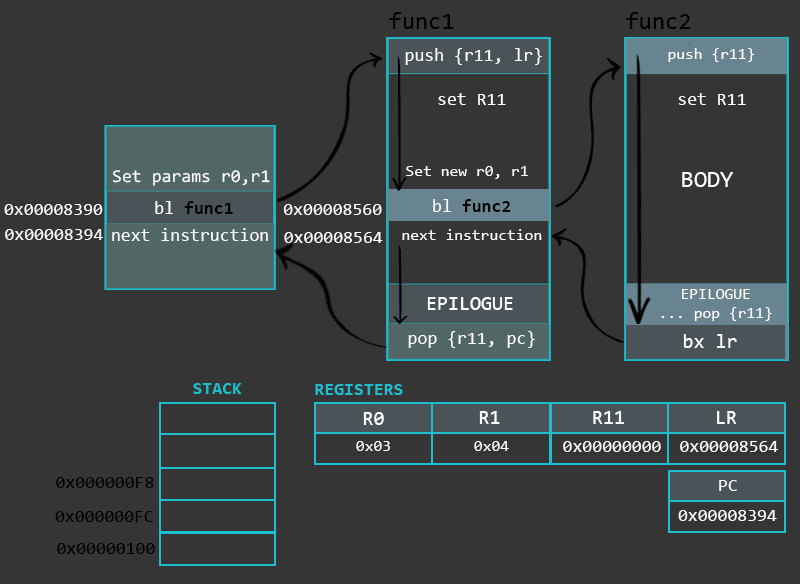
序言的目的是为了保存之前程序的执行状态(通过存储LR以及R11到栈上)以及设定栈以及局部函数变量。这些的步骤的实现可能根据编译器的不同有差异。通常来说是用PUSH/ADD/SUB这些指令。举个例子:
push {r11, lr} /* 保存R11与LR */
add r11, sp, #4 /* 设置栈帧底部,PUSH两个寄存器,SP加4后指向栈帧底部元素 */
sub sp, sp, #16 /* 在栈上申请相应空间 */
函数体部分就是函数本身要完成的任务了。这部分包括了函数自身的指令,或者跳转到其它函数等。下面这个是函数体的例子。
mov r0, #1 /* 设置局部变量(a=1),同时也是为函数max准备参数a */
mov r1, #2 /* 设置局部变量(b=2),同时也是为函数max准备参数b */
bl max /* 分支跳转调用函数max */
上面的代码也展示了调用函数前需要如何准备局部变量,以为函数调用设定参数。一般情况下,前四个参数通过R0-R3来传递,而多出来的参数则需要通过栈来传递了。函数调用结束后,返回值存放在R0寄存器中。所以不管max函数如何运作,我们都可以通过R0来得知返回值。而且当返回值位64位值时,使用的是R0与R1寄存器一同存储64位的值。
函数的最后一部分即结束收尾,这一部分主要是用来恢复程序寄存器以及回到函数调用发生之前的状态。我们需要先恢复SP栈指针,这个可以通过之前保存的栈帧指针寄存器外加一些加减操作做到(保证回到FP,LR的出栈位置)。而当我们重新调整了栈指针后,我们就可以通过出栈操作恢复之前保存的寄存器的值。基于函数类型的不同,POP指令有可能是结束收尾的最后一条指令。然而,在恢复后我们可能还需要通过BX指令离开函数。一个收尾的样例代码是这样的。
sub sp, r11, #4 /* 收尾操作开始,调整栈指针,有两个寄存器要POP,所以从栈帧底部元素再减4 */
pop {r11, pc} /* 收尾操作结束。恢复之前函数的栈帧指针,以及通过之前保存的LR来恢复PC。 */
总结一下:
- 序言设定函数环境
- 函数体实现函数逻辑功能,将结果存到R0
- 收尾恢复程序状态,回到调用发生的地方。
关于函数,有一个关键点我们要知道,函数的类型分为叶函数以及非叶函数。叶函数是指函数中没有分支跳转到其他函数指令的函数。非叶函数指包含有跳转到其他函数的分支跳转指令的函数。这两种函数的实现都很类似,当然也有一些小不同。这里我们举个例子来分析一下:
/* azeria@labs:~$ as func.s -o func.o && gcc func.o -o func && gdb func */
.global main
main:
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, #4 /* Setting up the bottom of the stack frame */
sub sp, sp, #16 /* End of the prologue. Allocating some buffer on the stack */
mov r0, #1 /* setting up local variables (a=1). This also serves as setting up the first parameter for the max function */
mov r1, #2 /* setting up local variables (b=2). This also serves as setting up the second parameter for the max function */
bl max /* Calling/branching to function max */
sub sp, r11, #4 /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame pointer from the stack, jumping to previously saved LR via direct load into PC */
max:
push {r11} /* Start of the prologue. Saving Frame Pointer onto the stack */
add r11, sp, #0 /* 设置栈帧底部,PUSH一个寄存器,SP加0后指向栈帧底部元素 */
sub sp, sp, #12 /* End of the prologue. Allocating some buffer on the stack */
cmp r0, r1 /* Implementation of if(a<b) */
movlt r0, r1 /* if r0 was lower than r1, store r1 into r0 */
add sp, r11, #0 /* 收尾操作开始,调整栈指针,有一个寄存器要POP,所以从栈帧底部元素再减0 */
pop {r11} /* restoring frame pointer */
bx lr /* End of the epilogue. Jumping back to main via LR register */
上面的函数main以及max函数,一个是非叶函数另一个是叶函数。就像之前说的非叶函数中有分支跳转到其他函数的逻辑,函数max中没有在函数体逻辑中包含有这类代码,所以是叶函数。
除此之外还有一点不同是两类函数序言与收尾的实现是有差异的。来看看下面这段代码,是关于叶函数与非叶函数的序言部分的差异的:
/* A prologue of a non-leaf function */
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, #4 /* Setting up the bottom of the stack frame */
sub sp, sp, #16 /* End of the prologue. Allocating some buffer on the stack */
/* A prologue of a leaf function */
push {r11} /* Start of the prologue. Saving Frame Pointer onto the stack */
add r11, sp, #0 /* Setting up the bottom of the stack frame */
sub sp, sp, #12 /* End of the prologue. Allocating some buffer on the stack */
一个主要的差异是,非叶函数需要在栈上保存更多的寄存器,这是由于非叶函数的本质决定的,因为在执行时LR寄存器会被修改,所以需要保存LR寄存器以便之后恢复。当然如果有必要也可以在序言期保存更多的寄存器。
下面这段代码可以看到,叶函数与非叶函数在收尾时的差异主要是在于,叶函数的结尾直接通过LR中的值跳转回去就好,而非叶函数需要先通过POP恢复LR寄存器,再进行分支跳转。
/* An epilogue of a leaf function */
add sp, r11, #0 /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11} /* restoring frame pointer */
bx lr /* End of the epilogue. Jumping back to main via LR register */
/* An epilogue of a non-leaf function */
sub sp, r11, #4 /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame pointer from the stack, jumping to previously saved LR via direct load into PC */
最后,我们要再次强调一下在函数中BL和BX指令的使用。在我们的示例中,通过使用BL指令跳转到叶函数中。在汇编代码中我们使用了标签,在编译过程中,标签被转换为对应的内存地址。在跳转到对应位置之前,BL会将下一条指令的地址存储到LR寄存器中这样我们就能在函数max完成的时候返回了。
BX指令在被用在我们离开一个叶函数时,使用LR作为寄存器参数。刚刚说了LR存放着函数调用返回后下一条指令的地址。由于叶函数不会在执行时修改LR寄存器,所以就可以通过LR寄存器跳转返回到main函数了。同样BX指令还会帮助我们切换ARM/Thumb模式。同样这也通过LR寄存器的最低比特位来完成,0代表ARM模式,1代表Thumb模式。
最后,这张动图阐述了非叶函数调用叶函数时候的内部寄存器的工作状态。