RDS-SLAM:一种实时的语义分割框架。
摘要
在典型的视觉同步定位与映射(vSLAM)算法中,场景刚性是一个很强的假设。这种强烈的假设限制了大多数vSLAM在动态现实环境中的使用,而动态现实环境是一些相关应用的目标,如增强现实、语义映射、无人驾驶汽车和服务机器人。许多解决方案被提出,使用不同类型的语义分割方法(如Mask R-CNN, SegNet)来检测动态对象和去除异常值。然而,据我们所知,这类方法在其体系结构中等待跟踪线程的语义结果,处理时间取决于所使用的分割方法。本文提出了基于ORB-SLAM3的实时可视化动态SLAM算法RDS-SLAM,并添加了语义线程和基于语义的优化线程,实现了动态环境下的实时鲁棒跟踪和映射。这些新线程与其他线程并行运行,因此跟踪线程不再需要等待语义信息。此外,我们提出了一种尽可能获取最新语义信息的算法,从而使不同速度的分割方法能够统一使用。我们利用移动概率来更新和传播语义信息,它被保存在地图中,并使用数据关联算法来去除跟踪中的异常值。最后,我们利用TUM RGB-D公共数据集和Kinect摄像头对动态室内场景下的跟踪精度和实时性进行评估。
1 引言
同时定位和测绘(SLAM)[1]是许多应用的基础技术,如增强现实(AR),机器人和无人驾驶车辆(UA V)。Visual SLAM (vSLAM)[2]使用摄像头作为输入,在场景理解和决策中很有用。然而,强烈的场景刚性假设限制了大多数vSLAM在现实环境中的使用。动态对象将导致许多坏的或不稳定的数据关联,从而在SLAM过程中积累漂移。

例如,在图1中,假设$m_1$是一个人,它的位置在场景中变化。不良的或不稳定的数据关联(图1中的红线)将导致在动态环境下不正确的摄像机自运动估计。通常,vSLAM有两个基本要求:跟踪鲁棒性和实时性。因此,如何在人口稠密的场景中检测动态对象,防止跟踪算法实时使用与动态对象相关的数据关联,是实现vSLAM在现实世界中部署的挑战。
我们将解决方法分为两类:基于纯几何的[3]-[7]方法和基于语义的[8]-[13]方法。这些基于几何的方法不能去除所有潜在的动态对象,例如,坐着的人。这些物体上的特征是不可靠的,也需要从跟踪和绘图中删除。这些基于语义的方法使用语义分割或对象检测方法获得像素级的mask或潜在动态对象的bounding box。使用语义信息可以检测到坐着的人,并将其从跟踪和映射中移除,还可以建立静态对象的地图。通常,在基于语义的方法中,几何检验,如随机抽样一致(RANSAC)[14]和多视图几何,也被用来去除离群值。
这些基于语义的方法首先检测分割对象,然后从跟踪中移除异常值。跟踪线程在跟踪之前需要等待语义信息(摄像机运动估计),本文称之为blocked model模型(如图2所示)。它们的处理速度受所用语义切分方法耗时的限制。例如,Mask R-CNN分割一幅图像需要大约200ms[15],这将限制整个系统的实时性。

我们的主要挑战是如何在动态场景下使用不同速度运行的不同像素级语义分割方法实时执行vSLAM,如SegNet和Mask R-CNN。我们提出了一个语义线程来等待语义信息。它与跟踪线程并行运行,并且跟踪线程不需要等待段结果。因此,跟踪线程可以实时执行。本文将其称为non-blocked(无阻塞)模型。快速的分割方法(如SegNet)可以比慢的方法(如Mask R-CNN)更频繁地更新语义信息。虽然我们不能控制分割速度,但我们可以使用一种策略来获取尽可能最新的语义信息,以从当前框架中去除异常值。
因为语义线程与跟踪线程并行运行,所以我们使用地图点来保存和共享语义信息。如图1所示,我们利用移动概率更新和传播语义信息,根据移动概率阈值将地图点分为静态、动态和未知三类。这些分类的地图点将用于在跟踪中选择尽可能稳定的数据关联。
本文的主要贡献有: 1.我们提出了一种新的基于语义的实时动态vSLAM算法RDS-SLAM,它使跟踪线程不再需要等待语义结果。该方法在保持算法实时性的同时,有效地利用语义分割结果进行动态目标检测和离群点去除。
2.我们提出了一种关键帧选择策略,利用尽可能最新的语义信息,以统一的方式去除不同速度的语义分割方法中的异常值。
3.实验结果表明,该方法的实时性优于现有的同类方法。
本文的其余部分结构如下。第二部分讨论了相关工作。第三部分描述了系统概述。第四、五、六节详细说明了所提议方法的执行情况。第七节给出实验结果,第八节给出结论并讨论未来的工作。
2 相关工作
2.1 视觉SLAM(VISUAL SLAM)
vSLAM[2]可以分为基于特征的方法(feature-based methods)和直接方法(direct methods)。Mur-Artal介绍了ORB-SLAM2[16],一个完整的单目、双目和RGB-D相机的SLAM系统,它可以在各种环境的标准cpu上实时工作。该系统通过匹配当前帧和前一帧之间对应的ORB[17]特征来估计摄像机的自我运动,该系统有三个并行线程:跟踪、建图和回环。Carloset .提出了最新版本ORB-SLAM3[18],主要增加了两个创新点:1)基于特征点的紧耦合视觉惯性SLAM,完全依赖于最大先验估计(MAP);2)基于改进回环检测的新地点识别方法的多地图系统(ATLAS[19])。与基于特征的方法相比。例如,Kerl等人为RGB-D摄像机提出了一种密集视觉SLAM方法DVO[20],该方法可以最小化所有像素的光度误差和深度误差。然而,上述方法都不能解决动态对象的常见问题。实时检测和处理动态场景中的动态对象是vSLAM中一个具有挑战性的任务。
我们的工作建立在ORB-SLAM3[18]的实现。ORB-SLAM3中的概念:关键帧、共可见图、TLAS和Bundle调整(BA),也在我们的实现中使用。
2.1.1 关键帧
关键帧[18]是选定帧的子集,以避免在跟踪和优化时出现不必要的冗余。每个关键帧存储1)相机姿态的刚体变换,将点从世界到相机坐标系;2) ORB特性,是否与地图点相关联。本文采用与ORB-SLAM3相同的策略选择关键帧;如果满足以下所有条件,则选择一个关键帧:1)上一次全局重定位或最后一次关键帧插入已经过了了20帧;2)本地映射线程空闲;3)当前帧跟踪至少50点或低于参考关键帧的90%点。
2.1.2 共视图
共视图[16]被表示为一个无向加权图,其中每个节点是一个关键帧,边保存着通常观察到的映射点的数量。
2.1.3 ATLAS
Atlas[19]是一个多地图表示,可以处理无限数量的子地图。在地图集中管理两种地图,即活动地图和非活动地图。当摄像机跟踪被认为丢失并且重新定位失败了时,活动地图变成非活动地图,并初始化一个新的地图。在图集中,关键帧和地图点使用共视图和生成树进行管理。
2.1.4 光束法平差(BA)
BA[21]是一种细化视觉重建的问题,以共同产生最优的三维结构和视觉参数估计。本地BA在本地映射线程中只用于优化摄像机姿态。闭环在姿态图优化后启动一个线程进行全BA,共同优化摄像机姿态和相应的地标。
2.2 基于几何的解决方案
Liet al.[5]提出了一种基于帧-关键帧配准的动态环境实时深度边缘RGB-D SLAM系统。它们只使用深度边缘点,这些点有一个相关的权重,表明它属于一个动态对象的概率。
Sunet .[6]利用量化深度图像的分割对像素进行分类,并计算连续RGB图像之间的强度差。
Tanet al.[3]提出了一种新的在线关键帧表示和更新方法来自适应地建模动态环境,使用一种新的基于先验的自适应RANSAC算法可以有效地去除异常值,即使在具有挑战性的情况下也可以可靠地估计摄像机姿态。
虽然在动态环境中基于几何的vslam解决方案在某种程度上限制了动态对象的效果,但也有一些限制:1)他们不能检测到临时保持静止但潜在的动态物体;2)缺乏语义信息,我们不能使用场景先验信息检测动态物体。
2.3 基于语义的解决方案
DS-SLAM:在ORB-SLAM2[16]上实现,结合语义分割网络(SegNet[22])和移动一致性检查,以减少动态对象的影响,并产生一个密集的语义八叉树地图[23]。DS-SLAM假设人身上的特征点最有可能是异常值。如果确定一个人是静态的,那么人的匹配点也可以用来预测相机的姿势。
DynaSLAM:也建立在ORB-SLAM2上,通过添加动态目标检测和背景修复功能,在单目、双目和RGB-D数据集的动态场景中有很好的鲁棒性。它可以通过多视图几何、深度学习或两者同时检测运动对象,并使用场景的静态地图来修复被动态对象遮挡的框架背景。它使用Mask R-CNN分割出所有的先验动态对象,如人或车辆。DynaSLAM II[24]紧密集成了多目标跟踪能力。但这种方法只适用于刚性物体。然而,在TUM[25]数据集的动态场景中,人们通过时而站时而坐的方式来改变自己的形状。
Detect-SLAM:基于ORB-SLAM2,将视觉SLAM与single-shot multi-box detector(SSD)[26]集成,使二者实现互利共赢。他们把特征点属于移动物体的概率称为移动概率。他们将关键点区分为四种状态:high-confidence static,low-confidence static, low-confidence dynamic,high-confidence dynamic 。考虑到检测的延迟和连续帧的空间一致性,使用SSD只使用关键帧的彩色图像进行检测,同时在跟踪线程中逐帧传播概率。一旦得到检测结果,他们将关键帧插入到局部地图中,更新局部地图上的移动概率。然后更新局部地图中与关键帧匹配的3D点的移动概率。
DM-SLAM:DM-SLAM[11]结合Mask R-CNN、光流和极线约束来判断离群值。Ego-motion Estima-tion模块估计相机的初始姿态,类似于DynaSLAM中的低成本跟踪模块。如果它们移动不剧烈,DM-SLAM还利用了先验动态对象中的特征,以减少去除所有先验动态对象而导致的特征减少的情况。
Fanet al.[8]提出了一种新的语义SLAM系统,在动态环境中具有更准确的点云图,他们使用BlizNet[27]获取图像中动态对象的Maskbounding box。
所有这些方法都使用block模型。他们会等待每一帧或关键帧的语义结果,然后再估计摄像机姿态。因此,它们的处理速度受到它们所使用的特定cnn模型的限制。在这篇论文中,我们提出了使用non-block模型的RDS-SLAM,并通过与那些方法的比较显示其实时性能。
3 系统视图

每一帧将首先通过跟踪线程。在最后一帧跟踪后,对当前帧的初始摄像机姿态进行估计,并通过局部地图跟踪进一步优化。在语义跟踪、基于语义优化和局部地图线程等方面,选取关键帧。我们在跟踪和局部地图线程中修改了几个模型,利用语义信息从摄像机的自我运动估计中去除异常值。在跟踪线程中,我们提出了一种数据关联算法,以尽可能地利用静态对象的特征。语义线程与其他线程并行运行,以避免阻塞跟踪线程,并将语义信息保存到atlas中。语义标签用于生成先验动态对象的Mask图像。利用语义信息更新与关键帧特征匹配的地图点的移动概率。最后,利用altas中的语义信息对摄像机姿态进行优化。我们将在下面的部分中介绍新特性和修改后的模型。我们将跳过与ORB-SLAM3相同的模块的详细说明。
4 语义线程
语义线程负责生成语义信息并将其更新到atlas地图中。在我们介绍语义线程的详细实现之前,我们用一个简单的例子来解释一般流程,如图4所示。

假设关键帧每两帧被选择一次。ORBSLAM3选择了关键帧,我们将它们按顺序插入到关键帧列表中。假设t=12时,KF2-KF6在KF内部。下一步是从KF中选择关键帧,从语义服务请求语义标签。本文将这一过程称为语义关键帧选择过程。我们从KF的头部(KF2)和后面(KF6)分别取一个关键帧请求语义标签。然后,利用语义标签S2和S6计算先验动态对象的Mask。接下来,我们更新atlas中存储的地图点的移动概率。移动概率稍后将用于从跟踪线程中移除异常值。
算法1给出了语义线程的详细实现。第一步是从关键帧列表KF中选择语义关键帧(第2行)。接下来,我们从语义模型中请求语义标签并返回语义标签SLs(第3行)。第4-8行是保存和处理返回的每个项目的语义结果。第6行是生成动态对象的Mask图像,第7行是更新存储在地图集中的移动概率。我们将按顺序介绍语义线程的每个子模块(见图3)。

4.1 语义关键帧选择算法
语义关键帧选择算法是为以后请求语义标签而选择关键帧。在使用不同的语义分割方法的同时,需要保证分割的实时性。但是,其中一些分割算法,如Mask R-CNN,比较耗时,如果对每个关键帧进行连续分割,可能无法获得新的语义信息。为了定量评估距离,我们定义了语义延迟,即拥有最新语义信息的语义标签(St)的最新帧id与当前帧id (Ft)之间的距离,如下所示:
图5显示了几种情况下的语义延迟。

一般的思路是按时间顺序分割每一帧或关键帧,如图5(a)所示。我们称这种模型为sequential segmentation model。
但是,在使用耗时的分割方法时,如图6蓝线所示,这将单调地增加时间延迟。

例如,在时间=10 (F10)时,语义模型完成了kf0 (F0)的分割,语义延迟 d=10。同样,在时间=40 (F40)时,语义延迟变为34。也就是说,具有语义信息的最后一帧在当前帧之后34帧。当前帧无法获取最新的语义信息。
为了缩短距离,假设我们同时连续分割两帧(图5(b))。当KF0和KF1同时分割时,延迟变为12−2=10。延迟仍呈线性增长,如图6中红线所示。
为了进一步缩短语义延迟,我们使用了一个双向模型(bi-directional model)。我们不按顺序分割关键帧。相反,我们从列表的前面和后面使用关键帧来进行语义分割,尽可能使用最新的语义信息,如图5(c)和图6中的黄线所示。语义延迟成为常量。在实际应用中,双向模型中的时延并不总是10。这个距离受到使用的分割方法、关键帧选择的频率和相关线程的处理速度的影响。图7左侧为语义关键帧选择示例,图7右侧为向语义模型/服务器请求语义信息的时间线。

我们从KF的头部和后部提取关键帧来请求语义标签。(第1轮)在t=2时,选择两个关键帧KF0和KF1。分割在t=12完成。这时,新的关键帧被选择,然后插入到KF中(见第2轮)。然后我们取前面的KF2和后面的KF6两个元素来请求语义标签。在时间=22时,我们收到语义结果并继续下一轮(第3轮)。
如果我们在KF列表的尾部分割关键帧,我们可以获得相对新的信息。那么为什么我们还要分割列表前面的关键帧呢?与block模型不同,在我们的方法中,前几帧(如果使用mask r - cnn大约10帧)没有语义信息。由于跟踪线程的处理速度通常比这些线程快,vSLAM可能已经因为动态对象积累了更大的错误。因此,我们需要使用语义信息来纠正这些漂移错误,将KF列表前面的关键帧按顺序提供给基于语义的优化线程,以纠正/优化摄像机姿态。
4.2 语义分割
在我们的实验中,我们使用了两个不同速度的模型,Mask R-CNN(较慢)和SegNet(较快),如图8所示。

Mask R-CNN[15]使用MS COCO[28]进行训练,它具有像素级语义分割结果和实例标签。我们基于Matterport的TensorFlow版本实现了它。SegNet使用Caffe实现,使用PASCAL VOC 2012数据集进行训练,其中提供了20个类。我们没有使用TUM数据集来改进网络,因为SLAM通常运行在未知的环境中。
4.3 语义Mask生成
我们将实例分割结果的所有二值掩模图像合并成一张掩模图像,用于生成人的掩模图像(图8)。然后利用掩模计算地图点的先验移动概率。在实际应用中,由于对物体边界的分割有时是不可靠的,直接应用掩模图像无法检测出边界上的特征,如图9(a)所示。

因此,我们使用形态滤波器扩展掩模,以包括动态对象的边缘,如图9(b)所示。
4.4 移动概率更新
为了不等待语义信息进入跟踪线程,将语义分割与跟踪分离。我们利用移动概率将语义信息从语义线程传递到跟踪线程。利用移动概率来检测和去除跟踪中的异常值。
4.1.1 移动概率的定义
我们知道,vSLAM通常是在一个未知的环境中运行,如果CNN网络没有根据当前环境进行良好的训练或细化,语义结果并不总是健壮的(图10)。

为了检测离群点,考虑帧间的时空一致性,而不是仅仅使用一帧的语义结果,是更加合理的。我们利用移动概率来利用连续关键帧的语义信息。
我们定义每个地图点在当前时刻的移动概率 $p(m_t^{i},m_t^{i}\in M)$ 如图11所示。

如果地图点的移动概率更接近1,那么它的状态就更有可能是动态的。如果地图点更接近于零,那么它就越静态。为了简化,我们将地图点在时间点$i$上的移动概率$p(m_t^{i})$简称为$p(m_t)$。
每个地图点有两种状态$(M)$,动态和静态,初始概率设置为0.5$bel(m_0)$。
4.1.2 观察移动概率的定义
考虑到语义分割并非100%准确,我们将观察移动概率定义为:
α和β值是人工给出的,这与语义切分的准确性有关。在实验中,我们将α和β设置为0.9,通过补充语义分割是相当可靠的。
4.1.3 移动概率更新
基于观察$z_{1:t}$(语义分割)和初始状态$m_0$预测当前时间$bel(m_t)$,的移动概率。我们将移动概率更新问题表述为贝叶斯滤波器问题:
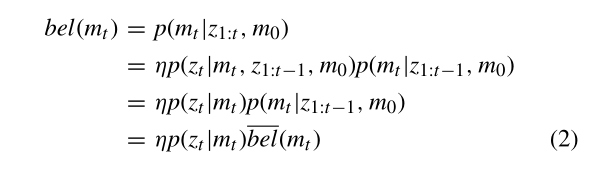
在等式2中,利用了贝叶斯规则和条件独立性,即当前观测$z_t$只依赖于当前状态$m_t, \eta$是一个常数。预测,$\overline{b e l}\left(m_{t}\right)$的计算方法为:

在等式3中,我们假设我们的状态是完整的。这意味着,如果我们知道之前的状态$m_{t-1}$,过去的测量没有传达关于状态$m_t$的信息。我们假设状态转移概率$p\left(m_{t}=d \mid m_{t-1}=s\right)=0$和$p\left(m_{t}=d \mid m_{t-1}=d\right)=1$,因为我们无法检测到物体的突然变化。
$\eta$由$\left(bel\left(m_{t}=d\right)+bel\left(m_{t}=s\right)\right) / 2$ 计算得到。地图点属于动态的概率计算方法为:
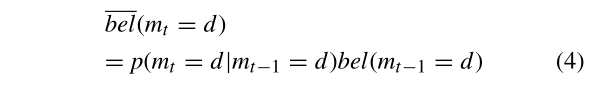
4.1.4 静态和动态点的判断
利用预定义的概率阈值$\theta_{d}$和$\theta_{s}$判断一个点是动态的还是静态的(见图11)。在实验中分别设为0.6和0.4。
