ARM汇编入门笔记。
ARM汇编入门笔记,包含常见的精简指令集编程汇总。
前言
ARM汇编的基础知识包括:
- Part 1:ARM汇编介绍
- Part 2:数据类型寄存器
- Part 3: ARM指令集
- Part 4: 内存相关指令:加载以及存储
- Part 5:重复性加载及存储
- Part 6: 分支和条件执行
- Part 7:栈以及函数
为了能跟着这个系列教程动手实践,你可以准备一个ARM的运行环境。如果你没有ARM设备(比如说树莓派或者手机),你可以通过QEMU来创建一个,教程在这(https://azeria-labs.com/emulate-raspberry-pi-with-qemu/)。如果你对于GDB调试的基础命令不熟悉的话,可以通过这个(https://azeria-labs.com/debugging-with-gdb-introduction/)学习。在这篇教程中,我们的核心关注点为32位的ARM,相关的例子在ARMv6下编译。
1 ARM 汇编介绍
1.1 ARM VS. INTEL
ARM处理器Intel处理器有很多不同,但是最主要的不同怕是指令集了。Intel属于复杂指令集(CISC)处理器,有很多特性丰富的访问内存的复杂指令集。因此它拥有更多指令代码以及取址都是,但是寄存器比ARM的要少。复杂指令集处理器主要被应用在PC机,工作站以及服务器上。
ARM属于简单指令集(RISC)处理器,所以与复杂指令集先比,只有简单的差不多100条指令集,但会有更多的寄存器。与Intel不同,ARM的指令集仅仅操作寄存器或者是用于从内存的加载/储存过程,这也就是说,简单的加载/存储指令即可访问到内存。这意味着在ARM中,要对特定地址中存储的的32位值加一的话,仅仅需要从内存中加载到寄存器,加一,再从寄存器储存到内存即可。
简单的指令集既有好处也有坏处。一个好处就是代码的执行变得更快了。(RISC指令集允许通过缩短时钟周期来加速代码执行)。坏处就是更少的指令集也要求了编写代码时要更加注意指令间使用的关系以及约束。还有重要的一点,ARM架构有两种模式,ARM模式和Thumb模式。Thumb模式的代码只有2或者4字节。
ARM与X86的不同还体现在:
- ARM中很多指令都可以用来做为条件执行的判断依据
- X86与X64机器码使用小端格式
- ARM机器码在版本3之前是小端。但是之后默认采用大端格式,但可以设置切换到小端。
除了以上这些ARM与Intel间的差异,ARM自身也有很多版本。本系列教程旨在尽力保持通用性的情况下来讲讲ARM的工作流程。而且当你懂得了这个形式,学习其他版本的也很容易了。在系列教程中使用的样例都是在32位的ARMv6下运行的,所以相关解释也是主要依赖这个版本的。
| ARM 家族 | ARM 架构 |
|---|---|
| ARM7 | ARM v4 |
| ARM9 | ARM v5 |
| ARM11 | ARM v6 |
| Cortex-A | ARM v7-A |
| Cortex-R | ARM v7-R |
| Cortex-M | ARM v7-M |
不同版本的ARM命名也是有些复杂:
1.2 写ARM汇编
在开始用ARM汇编做漏洞利用开发之前,还是需要先学习下基础的汇编语言知识的。为什么我们需要ARM汇编呢,用正常的变成语言写不够么?的确不够,因为如果我们想做逆向工程,或者理解相关二进制程序的执行流程,构建我们自己的ARM架构的shellcode,ROP链,以及调试ARM应用,这些都要求先懂得ARM汇编。当然你也不需要学习的太过深入,足够做逆向工作以及漏洞利用开发刚刚好。如果有些知识要求先了解一些背景知识,别担心,这些知识也会在本系列文章里面介绍到的。当然如果你想学习更多,也可以去本文末尾提供的相关链接学习。
ARM汇编,是一种更容易被人们接受的汇编语言。当然我们的计算机也不能直接运行汇编代码,还是需要编译成机器码的。通过编译工具链中as程序来将文件后缀为”.s”的汇编代码编译成机器码。写完汇编代码后,一般保存后缀为”.s”的文件,然后你需要用as编译以及用ld链接程序:
$ as program.s -o program.o
$ ld program.o -o program

1.3 汇编语言本质
让我们来看看汇编语言的底层本质。在最底层,只有电路的电信号。信号被格式化成可以变化的高低电平0V(off)或者5V(on)。但是通过电压变化来表述电路状态是繁琐的,所以用0和1来代替高低电平,也就有了二进制格式。由二进制序列组成的组合便是最小的计算机处理器工作单元了,比如下面的这句机器码序列就是例子。
1110 0001 1010 0000 0010 0000 0000 0001
看上去不错,但是我们还是不能记住这些组合的含义。所以,我们需要用助记符和缩写来帮助我们记住这些二进制组合。这些助记符一般是连续的三个字母,我们可以用这些助记符作为指令来编写程序。这种程序就叫做汇编语言程序。用以代表一种计算机的机器码的助记符集合就叫做这种计算机汇编语言。因此,汇编语言是人们用来编写程序的最底层语言。同时指令的操作符也有对应的助记符,比如:
MOV R2, R1
现在我们知道了汇编程序是助记符的文本信息集合,我们需要将其转换成机器码。就像之前的,在GNU Binutils(https://www.gnu.org/software/binutils/)工程中提供了叫做as的工具。使用汇编工具去将汇编语言转换成机器码的过程叫做汇编(assembling)。
总结一下,在这篇中我们学习了计算机是通过由0101代表高低电平的机器码序列来进行运算的。我们可以使用机器码去让计算机做我们想让它做的事情。不过因为我们不能记住机器码,我们使用了缩写助记符来代表有相关功能的机器码,这些助记符的集合就是汇编语言。最后我们使用汇编器将汇编语言转换成机器可以理解的机器码。当然,在更高级别的语言编译生成机器码过程中,核心原理也是这个。
1.4 拓展阅读
- Whirlwind Tour of ARM Assembly(https://www.coranac.com/tonc/text/asm.htm).
- ARM assembler in Raspberry Pi (http://thinkingeek.com/arm-assembler-raspberry-pi/).
- Practical Reverse Engineering: x86, x64, ARM, Windows Kernel, Reversing Tools, and Obfuscation by Bruce Dang, Alexandre Gazet, Elias Bachaalany and Sebastien Josse.
- ARM Reference Manual(http://infocenter.arm.com/help/topic/com.arm.doc.dui0068b/index.html).
- Assembler User Guide(http://www.keil.com/support/man/docs/armasm/default.htm).
2 ARM汇编数据类型基础
与高级语言类似,ARM也支持操作不同的数据类型。
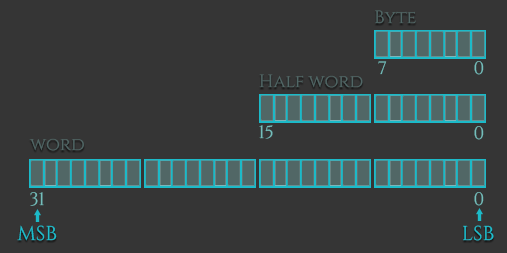
被加载或者存储的数据类型可以是无符号(有符号)的字(words,四字节),半字(halfwords,两字节),或者字节(bytes)。这些数据类型在汇编语言中的扩展后缀为-h或者-sh对应着半字,-b或者-sb对应着字节,但是对于字并没有对应的扩展。无符号类型与有符号类型的差别是:
- 符号数据类型可以包含正负数所以数值范围上更低些
- 无符号数据类型可以放得下很大的正数但是放不了负数
- 这有一些要求使用对应数据类型做存取操作的汇编指令示例:
ldr = 加载字,宽度四字节
ldrh = 加载无符号的半字,宽度两字节
ldrsh = 加载有符号的半字,宽度两字节
ldrb = 加载无符号的字节
ldrsb = 加载有符号的字节
str = 存储字,宽度四字节
strh = 存储无符号的半字,宽度两字节
strsh = 存储有符号的半字,宽度两字节
strb = 存储无符号的字节
strsb = 存储有符号的字节
2.1 字节序
在内存中有两种字节排布顺序,大端序(BE)或者小端序(LE)。两者的主要不同是对象中的每个字节在内存中的存储顺序存在差异。一般X86中是小端序,最低的字节存储在最低的地址上。在大端机中最高的字节存储在最低的地址上。
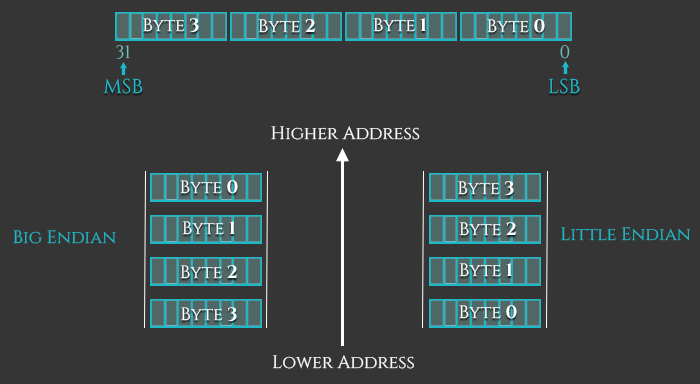
在版本3之前,ARM使用的是小端序,但在这之后就都是使用大端序了,但也允许切换回小端序。在我们样例代码所在的ARMv6中,指令代码是以[小端序排列对齐] (http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.ddi0301h/Cdfbbchb.html)。但是数据访问时采取大端序还是小端序使用程序状态寄存器(CPSR)的第9比特位来决定的。
2.2 ARM寄存器
寄存器的数量由ARM版本决定。根据ARM参考手册,在ARMv6-M与ARMv7-M的处理器中有30个32bit位宽度的通用寄存器。前16个寄存器是用户层可访问控制的,其他的寄存器在高权限进程中可以访问(但ARMv6-M与ARMv7-M除外)。我们仅介绍可以在任何权限模式下访问的16个寄存器。这16个寄存器分为两组:通用寄存器与有特殊含义的寄存器。
| # | 别名 | 用途 |
|---|---|---|
| R0 | - | 通用寄存器 |
| R1 | - | 通用寄存器 |
| R2 | - | 通用寄存器 |
| R3 | - | 通用寄存器 |
| R4 | - | 通用寄存器 |
| R5 | - | 通用寄存器 |
| R6 | - | 通用寄存器 |
| R7 | - | 一般放系统调用号 |
| R8 | - | 通用寄存器 |
| R9 | - | 通用寄存器 |
| R10 | - | 通用寄存器 |
| R11 | FP | 栈帧指针 |
| R12 | IP | 内部程序调用 |
| R13 | SP | 栈指针 |
| R14 | LR | 链接寄存器(一般存放函数返回地址) |
| R15 | PC | 程序计数寄存器 |
| CPSR | - | 当前程序状态寄存器 |
| ARM | 描述 | X86 |
|---|---|---|
| R0 | 通用寄存器 | EAX |
| R1-R5 | 通用寄存器 | EBX,ECX,EDX,ESI,EDI |
| R6-R10 | 通用寄存器 | - |
| R11(FP) | 栈帧指针 | EBP |
| R12 | 内部程序调用 | - |
| R13(SP) | 栈指针 | ESP |
| R14(LR) | 链接寄存器 | - |
| R14(LR) | <-程序计数器/机器码指针-> | EIP |
| CPSR | 程序状态寄存器 | EFLAGS |
下面这张表是ARM架构与寄存器与Intel架构寄存器的关系:
| ARM | 描述 | X86 |
|---|---|---|
| R0 | 通用寄存器 | EAX |
| R1-R5 | 通用寄存器 | EBX,ECX,EDX,ESI,EDI |
| R6-R10 | 通用寄存器 | - |
| R11(FP) | 栈帧指针 | EBP |
| R12 | 内部程序调用 | - |
| R13(SP) | 栈指针 | ESP |
| R14(LR) | 链接寄存器 | - |
| R14(LR) | <-程序计数器/机器码指针-> | EIP |
| CPSR | 程序状态寄存器 | EFLAGS |
R0-R12:用来在通用操作中存储临时的值,指针等。R0被用来存储函数调用的返回值。R7经常被用作存储系统调用号,R11存放着帮助我们找到栈帧边界的指针(之后会讲)。以及,在ARM的函数调用约定中,前四个参数按顺序存放在R0-R3中。
R13:SP(栈指针)。栈指针寄存器用来指向当前的栈顶。栈是一片来存储函数调用中相关数据的内存,在函数返回时会被修改为对应的栈指针。栈指针用来帮助在栈上申请数据空间。比如说你要申请一个字的大小,就会将栈指针减4,再将数据放入之前所指向的位置。
R14:LR(链接寄存器)。当一个函数调用发生,链接寄存器就被用来记录函数调用发生所在位置的下一条指令的地址。这么做允许我们快速的从子函数返回到父函数。
R15:PC(程序计数器)。程序计数器是一个在程序指令执行时自增的计数器。它的大小在ARM模式下总是4字节对齐,在Thumb模式下总是两字节对齐。当执行一个分支指令时,PC存储目的地址。在程序执行中,ARM模式下的PC存储着当前指令加8(两条ARM指令后)的位置,Thumb(v1)模式下的PC存储着当前指令加4(两条Thumb指令后)的位置。这也是X86与ARM在PC上的主要不同之处。
我们可以通过调试来观察PC的行为。我们的程序中将PC的值存到R0中同时包含了两条其他指令,来看看会发生什么。
.section .text
.global _start
_start:
mov r0, pc
mov r1, #2
add r2, r1, r1
bkpt
在GDB中,我们开始调试这段汇编代码:
gef> br _start
Breakpoint 1 at 0x8054
gef> run
在开始执行触发断点后,首先会在GDB中看到:
$r0 0x00000000 $r1 0x00000000 $r2 0x00000000 $r3 0x00000000
$r4 0x00000000 $r5 0x00000000 $r6 0x00000000 $r7 0x00000000
$r8 0x00000000 $r9 0x00000000 $r10 0x00000000 $r11 0x00000000
$r12 0x00000000 $sp 0xbefff7e0 $lr 0x00000000 $pc 0x00008054
$cpsr 0x00000010
0x8054 <_start> mov r0, pc <- $pc
0x8058 <_start+4> mov r0, #2
0x805c <_start+8> add r1, r0, r0
0x8060 <_start+12> bkpt 0x0000
0x8064 andeq r1, r0, r1, asr #10
0x8068 cmnvs r5, r0, lsl #2
0x806c tsteq r0, r2, ror #18
0x8070 andeq r0, r0, r11
0x8074 tsteq r8, r6, lsl #6
可以看到在程序的开始PC指向0x8054这个位置即第一条要被执行的指令,那么此时我们使用GDB命令si,执行下一条机器码。下一条指令是把PC的值放到R0寄存器中,所以应该是0x8054么?来看看调试器的结果。
$r0 0x0000805c $r1 0x00000000 $r2 0x00000000 $r3 0x00000000
$r4 0x00000000 $r5 0x00000000 $r6 0x00000000 $r7 0x00000000
$r8 0x00000000 $r9 0x00000000 $r10 0x00000000 $r11 0x00000000
$r12 0x00000000 $sp 0xbefff7e0 $lr 0x00000000 $pc 0x00008058
$cpsr 0x00000010
0x8058 <_start+4> mov r0, #2 <- $pc
0x805c <_start+8> add r1, r0, r0
0x8060 <_start+12> bkpt 0x0000
0x8064 andeq r1, r0, r1, asr #10
0x8068 cmnvs r5, r0, lsl #2
0x806c tsteq r0, r2, ror #18
0x8070 andeq r0, r0, r11
0x8074 tsteq r8, r6, lsl #6
0x8078 adfcssp f0, f0, #4.0
当然不是,在执行0x8054这条位置的机器码时,PC已经读到了两条指令后的位置也就是0x805c(见R0寄存器)。所以我们以为直接读取PC寄存器的值时,它指向的是下一条指令的位置。但是调试器告诉我们,PC指向当前指令向后两条机器码的位置。这是因为早期的ARM处理器总是会先获取当前位置后两条的机器码。这么做的原因也是确保与早期处理器的兼容性。
2.3 当前程序状态寄存器(CPSR)
当你用GDB调试ARM程序的的时候你能会可以看见Flags这一栏(GDB配置插件GEF后就可以看见了,或者直接在GDB里面输入flags也可以)。

图中寄存器$CSPR显示了当前状态寄存器的值,Flags里面出现的thumb,fast,interrupt,overflow,carry,zero,negative就是来源于CSPR寄存器中对应比特位的值。ARM架构的N,Z,C,V与X86架构EFLAG中的SF,ZF,CF,OF相对应。这些比特位在汇编级别的条件执行或者循环的跳出时,被用作判断的依据。

上图展示了32位的CPSR寄存器的比特位含义,左边是最大比特位,右边是最小比特位。每个单元代表一个比特。这一个个比特的含义都很丰富:
| 标记 | 含义 |
|---|---|
| N(Negative) | 指令结果为负值时置1 |
| Z(Zero) | 指令结果为零值时置1 |
| C(Carry) | 对于加法有进位则置1,对于减法有借位则置0 |
| V(Overflow) | 指令结果不能用32位的二进制补码存储,即发生了溢出时置1 |
| E(Endian) | 小端序置0,大端序置1 |
| T(Thumb) | 当为Thumb模式时置1,ARM模式置0 |
| M(Mode) | 当前的权限模式(用户态,内核态) |
| J(Jazelle) | 允许ARM处理器去以硬件执行java字节码的状态标示 |
假设我们用CMP指令去比较1和2,结果会是一个负数因为1-2=-1。然而当我们反过来用2和1比较,C位将被设定,因为在一个较大的数上减了较小的数,没有发生借位。当我们比较两个相同的数比如2和2时,由于结果是0,Z标志位将被置一。注意CMP指令中被使用的寄存器的值并不会被修改,其计算结果仅仅影响到CPSR寄存器中的状态位。
在开了GEF插件的GDB中,计算结果如下图:在这里我们比较的两个寄存器是R1和R0,所以执行后的flag状态如下图。

Carry位Flag被设置的原因是CMP R1,R0会去拿4和2做比较。因为我们用以个较大的数字去减一个较少的数字,没有发生借位。Carry位便被置1。相反的,如果是CMP R0,R1那么Negative位会被置一。
APSR包含以下ALU状态标志:
N - 当操作结果为负数时设置。
Z - 当操作结果为零时设置。
C - 当操作结果导致进位时设置。
V - 当操作导致溢出时设置。
进位会在以下情况下发生:
- 如果加法的结果大于或等于$2^32$
- 如果减法的结果为正数或零
- 在移动或逻辑指令中进行行内移位操作时产生。
- 如果加法、减法或比较的结果大于或等于$2^31$,或小于$2^31$,则会发生溢出。
3 ARM汇编常用指令集
3.1 ARM模式与THUMB模式
ARM处理器有两个主要的操作状态,ARM模式以及Thumb模式(Jazelle模式先不考虑)。这些模式与特权模式并不冲突。SVC模式既可以在ARM下调用也可以在Thumb下调用。只不过两种状态的主要不同是指令集的不同,ARM模式的指令集宽度是32位而Thumb是16位宽度(但也可以是32位)。知道何时以及如何使用Thumb模式对于ARM漏洞利用的开发尤其重要。当我们写ARM的shellcode时候,我们需要尽可能的少用NULL以及使用16位宽度的Thumb指令以精简代码。
不同版本ARM,其调用约定不完全相同,而且支持的Thumb指令集也是不完全相同。在某些版本山,ARM提出了扩展型Thumb指令集(也叫Thumbv2),允许执行32位宽的Thumb指令以及之前版本不支持的条件执行。为了在Thumb模式下使用条件执行指令,Thumb提出了”IT”分支指令。然而,这条指令在之后的版本又被更改移除了,说是为了让一些事情变得更加简单方便。我并不清楚各个版本的ARM架构所支持的具体的ARM/Thumb指令集,而且我也的确不想知道。我觉得你也应该不用深究这个问题。因为你只需要知道你设备上的关键ARM版本所支持的Thumb指令集就可以了。以及ARM信息中心可以帮你弄清楚你的ARM版本到底是多少。
就像之前说到的,Thumb也有很多不同的版本。不过不同的名字仅仅是为了区分不同版本的Thumb指令集而已(也就是对于处理器来说,这些指令永远都是Thumb指令)。
- Thumb-1(16位宽指令集):在ARMv6以及更早期的版本上使用。
- Thumb-2(16位/32位宽指令集):在Thumb-1基础上扩展的更多的指令集(在ARMv6T2以及ARMv7即很多32位Android手机所支持的架构上使用)
-
Thumb-EE:包括一些改变以及对于动态生成代码的补充(即那些在设备上执行前或者运行时编译的代码) ARM与Thumb的不同之处在于:
- 对于条件执行指令(不是条件跳转指令):所有的ARM状态指令都支持条件执行。一些版本的ARM处理器上允许在Thumb模式下通过IT汇编指令进行条件执行。条件执行减少了要被执行的指令数量,以及用来做分支跳转的语句,所以具有更高的代码密度。
- ARM模式与Thumb模式的32位指令:Thumb的32位汇编指令都有类似于a.w的扩展后缀。
- 桶型移位是另一种独特的ARM模式特性。它可以被用来减少指令数量。比如说,为了减少使用乘法所需的两条指令(乘法操作需要先乘2然后再把结果用MOV存储到另一个寄存器中),就可以使用在MOV中自带移位乘法操作的左移指令(
Mov R1, R0, LSL #1)。
在ARM模式与Thumb模式间切换的话,以下两个条件之一必须满足:
- 我们可以在使用分支跳转指令BX(branch and exchange)或者分支链接跳转指令BLX(branch,link and exchange)时,将目的寄存器的最低位置为1。之后的代码执行就会在Thumb模式下进行。你也许会好奇这样做目标跳转地址不就有对齐问题了么,因为代码都是2字节或者4字节对齐的?但事实上这并不会造成问题,因为处理器会直接忽略最低比特位的标识。更多的细节我们会在第6篇中解释。
- 我们之前有说过,在CPSR当前程序状态寄存器中,T标志位用来代表当前程序是不是在Thumb模式下运行的。
3.2 ARM指令集规律含义
这一节的目的是简要的介绍ARM的通用指令集。知道每一句汇编指令是怎么操作使用,相互关联,最终组成程序是很重要的。之前说过,汇编语言是由构建机器码块的指令组成。所以ARM指令通常由助记符外加一到两个跟在后面的操作符组成,如下面的模板所示:
MNEMONIC{S}{condition} {Rd}, Operand1, Operand2
助记符{是否使用CPSR}{是否条件执行以及条件} {目的寄存器}, 操作符1, 操作符2
由于ARM指令的灵活性,不是全部的指令都满足这个模板,不过大部分都满足了。下面来说说模板中的含义:
MNEMONIC - 指令的助记符如ADD
{S} - 可选的扩展位,如果指令后加了S,则需要依据计算结果更新CPSR寄存器中的条件跳转相关的FLAG
{condition} - 如果机器码要被条件执行,那它需要满足的条件标示
{Rd} - 存储结果的目的寄存器
Operand1 - 第一个操作数,寄存器或者是一个立即数
Operand2 - 第二个(可变的)操作数,可以是一个立即数或者寄存器或者有偏移量的寄存器
当助记符,S,目的寄存器以及第一个操作数都被声明的时候,条件执行以及第二操作数需要一些声明。因为条件执行是依赖于CPSR寄存器的值的,更精确的说是寄存器中的一些比特位。第二操作数是一个可变操作数,因为我们可以以各种形式来使用它,立即数,寄存器,或者有偏移量的寄存器。举例来说,第二操作数还有如下操作:
#123 - 立即数
Rx - 寄存器比如R1
Rx, ASR n - 对寄存器中的值进行算术右移n位后的值
Rx, LSL n - 对寄存器中的值进行逻辑左移n位后的值
Rx, LSR n - 对寄存器中的值进行逻辑右移n位后的值
Rx, ROR n - 对寄存器中的值进行循环右移n位后的值
Rx, RRX - 对寄存器中的值进行带扩展的循环右移1位后的值
在知道了这个机器码模板后,然我们试着去理解这些指令:
ADD R0, R1, R2 - 将第一操作数R1的内容与第二操作数R2的内容相加,将结果存储到R0中。
ADD R0, R1, #2 - 将第一操作数R1的内容与第二操作数一个立即数相加,将结果存到R0中
MOVLE R0, #5 - 当满足条件LE(Less and Equal,小于等于0)将第二操作数立即数5移动到R0中,注意这条指令与MOVLE R0, R0, #5相同
MOV R0, R1, LSL #1 - 将第二操作数R1寄存器中的值逻辑左移1位后存入R0
| 指令 | 含义 | 指令 | 含义 |
|---|---|---|---|
| MOV | 移动数据 | EOR | 比特位异或 |
| MVN | 取反码移动数据 | LDR | 加载数据 |
| ADD | 数据相加 | STR | 存储数据 |
| SUB | 数据相减 | LDM | 多次加载 |
| MUL | 数据相乘 | STM | 多次存储 |
| LSL | 逻辑左移 | PUSH | 压栈 |
| LSR | 逻辑右移 | POP | 出栈 |
| ASR | 算术右移 | B | 分支跳转 |
| ROR | 循环右移 | BL | 链接分支跳转 |
| CMP | 比较操作 | BX | 分支跳转切换 |
| AND | 比特位与 | BLX | 链接分支跳转切换 |
4 ARM汇编内存访问相关指令
ARM使用加载-存储模式控制对内存的访问,这意味着只有加载/存储(LDR或者STR)才能访问内存。尽管X86中允许很多指令直接操作在内存中的数据,但ARM中依然要求在操作数据前,必须先从内存中将数据取出来。这就意味着如果要增加一个32位的在内存中的值,需要做三种类型的操作(加载,加一,存储)将数据从内存中取到寄存器,对寄存器中的值加一,再将结果放回到内存中。
为了解释ARM架构中的加载和存储机制,我们准备了一个基础的例子以及附加在这个基础例子上的三种不同的对内存地址的便宜访问形式。每个例子除了STR/LDR的偏移模式不同外,其余的都一样。而且这个例子很简单,最佳的实践方式是用GDB去调试这段汇编代码。
第一种偏移形式:立即数作为偏移
- 地址模式:用作偏移
- 地址模式:前向索引
- 地址模式:后向索引
第二种偏移形式:寄存器作为偏移
- 地址模式:用作偏移
- 地址模式:前向索引
- 地址模式:后向索引
第三种偏移形式:寄存器缩放值作为偏移
- 地址模式:用作偏移
- 地址模式:前向索引
- 地址模式:后向索引
4.1 基础样例代码
通常,LDR被用来从内存中加载数据到寄存器,STR被用作将寄存器的值存放到内存中。

LDR R2, [R0] @ [R0] - 数据源地址来自于R0指向的内存地址
@ LDR操作:从R0指向的地址中取值放到R2中
STR R2, [R1] @ [R1] - 目的地址来自于R1在内存中指向的地址
@ STR操作:将R2中的值放到R1指向的地址中
样例程序的汇编代码及解释如下:
.data /* 数据段是在内存中动态创建的,所以它的在内存中的地址不可预测*/
var1: .word 3 /* 内存中的第一个变量 */
var2: .word 4 /* 内存中的第二个变量 */
.text /* 代码段开始 */
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1] @ 将R2中的值0x3存放到R1做指向的地址
bkpt
adr_var1: .word var1 /* var1的地址助记符 */
adr_var2: .word var2 /* var2的地址助记符 */
在底部我们有我们的文字标识池(在代码段中用来存储常量,字符串,或者偏移等的内存,可以通过位置无关的方式引用),分别用adr_var1和adr_var2存储着变量var1和var2的内存地址(var1和var2的值在数据段定义)。第一条LDR指令将变量var1的地址加载到寄存器R0。第二条LDR指令同样将var2的地址加载到寄存器R1。之后我们将存储在R0指向的内存地址中的值加载到R2,最后将R2中的值存储到R1指向的内存地址中。
当我们加载数据到寄存器时,方括号“[]”意味着:将其中的值当做内存地址,并取这个内存地址中的值加载到对应寄存器。
当我们存储数据到内存时,方括号“[]”意味着:将其中的值当做内存地址,并向这个内存地址所指向的位置存入对应的值。
听者好像有些抽象,所以再来看看这个动画吧:

同样的再来看看的这段代码在调试器中的样子。
gef> disassemble _start
Dump of assembler code for function _start:
0x00008074 <+0>: ldr r0, [pc, #12] ; 0x8088 <adr_var1>
0x00008078 <+4>: ldr r1, [pc, #12] ; 0x808c <adr_var2>
0x0000807c <+8>: ldr r2, [r0]
0x00008080 <+12>: str r2, [r1]
0x00008084 <+16>: bx lr
End of assembler dump.
可以看到此时的反汇编代码和我们编写的汇编代码有出入了。前两个LDR操作的源寄存器被改成了[pc,#12]。这种操作叫做PC相对地址。因为我们在汇编代码中使用的只是数据的标签,所以在编译时候编译器帮我们计算出来了与我们想访问的文字标识池的相对便宜,即PC+12`。你也可以看汇编代码中手动计算验证这个偏移是正确的,以adr_var1为例,执行到8074时,其当前有效PC与数据段还有三个四字节的距离,所以要加12。关于PC相对取址我们接下来还会接着介绍。
PS:如果你对这里的PC的地址有疑问,可以看外面第二篇关于程序执行时PC的值的说明,PC是指向当前执行指令之后第二条指令所在位置的,在32位ARM模式下是当前执行位置加偏移值8,在Thumb模式下是加偏移值4。这也是与X86架构PC的区别之所在。

4.2 第一种偏移形式:立即数作偏移
STR Ra, [Rb, imm]
LDR Ra, [Rc, imm]
在这段汇编代码中,我们使用立即数作为偏移量。这个立即数被用来与一个寄存器中存放的地址做加减操作(下面例子中的R1),以访问对应地址偏移处的数据。
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, #2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加2所指向地址处。
str r2, [r1, #4]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加4所指向地址处,之后R1寄存器中存储的值加4,也就是R1=R1+4。
ldr r3, [r1], #4 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中存储的值加4,也就是R1=R1+4。
bkpt
adr_var1: .word var1
adr_var2: .word var2
让我们把上面的这段汇编代码编译一下,并用GDB调试起来看看真实情况。
$ as ldr.s -o ldr.o
$ ld ldr.o -o ldr
$ gdb ldr
在GDB(使用GEF插件)中,我们对_start下一个断点并继续运行程序。
gef> break _start
gef> run
...
gef> nexti 3 /* 向后执行三条指令 */
执行完上述GDB指令后,在我的系统的寄存器的值现在是这个样子(在你的系统里面可能不同):
$r0 : 0x00010098 -> 0x00000003
$r1 : 0x0001009c -> 0x00000004
$r2 : 0x00000003
$r3 : 0x00000000
$r4 : 0x00000000
$r5 : 0x00000000
$r6 : 0x00000000
$r7 : 0x00000000
$r8 : 0x00000000
$r9 : 0x00000000
$r10 : 0x00000000
$r11 : 0x00000000
$r12 : 0x00000000
$sp : 0xbefff7e0 -> 0x00000001
$lr : 0x00000000
$pc : 0x00010080 -> <_start+12> str r2, [r1]
$cpsr : 0x00000010
下面来分别调试这三条关键指令。首先执行基于地址偏移的取址模式的STR操作了。就会将R2(0x00000003)中的值存放到R1(0x0001009c)所指向地址偏移2的位置0x1009e。下面一段是执行完对应STR操作后对应内存位置的值。
gef> nexti
gef> x/w 0x1009e
0x1009e <var2+2>: 0x3
下一条STR操作使用了基于索引前置修改的取址模式。这种模式的识别特征是(!)。区别是在R2中的值被存放到对应地址后,R1的值也会被更新。这意味着,当我们将R2中的值0x3存储到R1(0x1009c)的偏移4之后的地址0x100A0后,R1的值也会被更新到为这个地址。下面一段是执行完对应STR操作后对应内存位置以及寄存器的值。
gef> nexti
gef> x/w 0x100A0
0x100a0: 0x3
gef> info register r1
r1 0x100a0 65696
最后一个LDR操作使用了基于索引后置的取址模式。这意味着基础寄存器R1被用作加载的内存地址,之后R1的值被更新为R1+4。换句话说,加载的是R1所指向的地址而不是R1+4所指向的地址,也就是0x100A0中的值被加载到R3寄存器,然后R1寄存器的值被更新为0x100A0+0x4也就是0x100A4。下面一段是执行完对应LDR操作后对应内存位置以及寄存器的值。
gef> info register r1
r1 0x100a4 65700
gef> info register r3
r3 0x3 3
下图是这个操作发生的动态示意图。

4.3 第二种偏移形式:寄存器作偏移
STR Ra, [Rb, Rc]
LDR Ra, [Rb, Rc]
在这个偏移模式中,寄存器的值被用作偏移。下面的样例代码展示了当试着访问数组的时候是如何计算索引值的。
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, r2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加R2寄存器的值所指向地址处。R1寄存器不会被修改。
str r2, [r1, r2]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加R2寄存器的值所指向地址处,之后R1寄存器中的值被更新,也就是R1=R1+R2。
ldr r3, [r1], r2 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中的值被更新也就是R1=R1+R2。
bx lr
adr_var1: .word var1
adr_var2: .word var2
下面来分别调试这三条关键指令。在执行完基于偏移量的取址模式的STR操作后,R2的值被存在了地址0x1009c + 0x3 = 0x1009F处。下面一段是执行完对应STR操作后对应内存位置的值。
gef> x/w 0x0001009F
0x1009f <var2+3>: 0x00000003
下一条STR操作使用了基于索引前置修改的取址模式,R1的值被更新为R1+R2的值。下面一段是执行完对应STR操作后寄存器的值。
gef> info register r1
r1 0x1009f 65695
最后一个LDR操作使用了基于索引后置的取址模式。将R1指向的值加载到R2之后,更新了R1寄存器的值(R1+R2 = 0x1009f + 0x3 = 0x100a2)。下面一段是执行完对应LDR操作后对应内存位置以及寄存器的值。
gef> info register r1
r1 0x100a2 65698
gef> info register r3
r3 0x3 3
下图是这个操作发生的动态示意图。

4.4 第三种偏移形式:寄存器缩放值作偏移
LDR Ra, [Rb, Rc, <shifter>]
STR Ra, [Rb, Rc, <shifter>]
在这种偏移形式下,第三个偏移量还有一个寄存器做支持。Rb是基址寄存器,Rc中的值作为偏移量,或者是要被左移或右移的<shifter>次的值。这意味着移位器shifter被用来用作缩放Rc寄存器中存放的偏移量。下面的样例代码展示了对一个数组的循环操作。同样的,我们也会用GDB调试这段代码。
.data
var1: .word 3
var2: .word 4
.text
.global _start
_start:
ldr r0, adr_var1 @ 将存放var1值的地址adr_var1加载到寄存器R0中
ldr r1, adr_var2 @ 将存放var2值的地址adr_var2加载到寄存器R1中
ldr r2, [r0] @ 将R0所指向地址中存放的0x3加载到寄存器R2中
str r2, [r1, r2, LSL#2] @ 取址模式:基于偏移量。R2寄存器中的值0x3被存放到R1寄存器的值加(左移两位后的R2寄存器的值)所指向地址处。R1寄存器不会被修改。
str r2, [r1, r2, LSL#2]! @ 取址模式:基于索引前置修改。R2寄存器中的值0x3被存放到R1寄存器的值加(左移两位后的R2寄存器的值)所指向地址处,之后R1寄存器中的值被更新,也就R1 = R1 + R2<<2。
ldr r3, [r1], r2, LSL#2 @ 取址模式:基于索引后置修改。R3寄存器中的值是从R1寄存器的值所指向的地址中加载的,加载之后R1寄存器中的值被更新也就是R1 = R1 + R2<<2。
bkpt
adr_var1: .word var1
adr_var2: .word var2
下面来分别调试这三条关键指令。在执行完基于偏移量的取址模式的STR操作后,R2被存储到的位置是[r1,r2,LSL#2],也就是说被存储到R1+(R2<<2)的位置了,如下图所示。
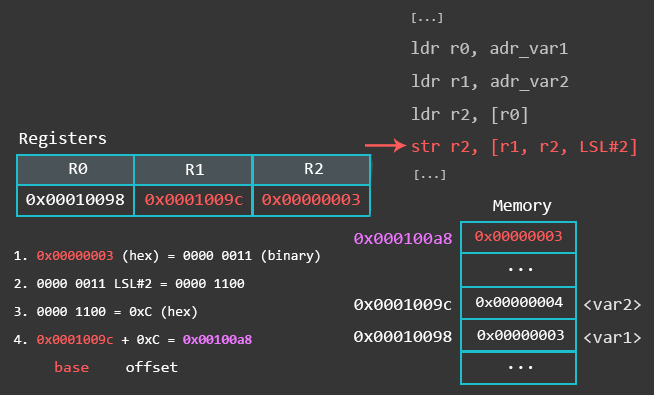
下一条STR操作使用了基于索引前置修改的取址模式,R1的值被更新为R1+(R2«2)的值。下面一段是执行完对应STR操作后寄存器的值。
gef> info register r1
r1 0x100a8 65704
最后一个LDR操作使用了基于索引后置的取址模式。将R1指向的值加载到R2之后,更新了R1寄存器的值(R1+R2 = 0x100a8 + (0x3<<2) = 0x100b4)。下面一段是执行完对应LDR操作后寄存器的值。
gef> info register r1
r1 0x100b4 65716
4.5 小结
LDR/STR的三种偏移模式:
- 立即数作为偏移
ldr r3, [r1, #4]
- 寄存器作为偏移
ldr r3, [r1, r2]
- 寄存器缩放值作为偏移
ldr r3, [r1, r2, LSL#2]
如何区分取址模式:
- 如果有一个叹号!,那就是索引前置取址模式,即使用计算后的地址,之后更新基址寄存器。
ldr r3, [r1, #4]!
ldr r3, [r1, r2]!
ldr r3, [r1, r2, LSL#2]!
- 如果在[]外有一个寄存器,那就是索引后置取址模式,即使用原有基址寄存器重的地址,之后再更新基址寄存器
ldr r3, [r1], #4
ldr r3, [r1], r2
ldr r3, [r1], r2, LSL#2
- 除此之外,就都是偏移取址模式了
ldr r3, [r1, #4]
ldr r3, [r1, r2]
ldr r3, [r1, r2, LSL#2]
- 地址模式:用作偏移
- 地址模式:前向索引
- 地址模式:后向索引
4.6 关于PC相对取址的LDR指令
有时候LDR并不仅仅被用来从内存中加载数据。还有如下这操作:
.section .text
.global _start
_start:
ldr r0, =jump /* 加载jump标签所在的内存位置到R0 */
ldr r1, =0x68DB00AD /* 加载立即数0x68DB00AD到R1 */
jump:
ldr r2, =511 /* 加载立即数511到R2 */
bkpt
这些指令学术上被称作伪指令。但我们在编写ARM汇编时可以用这种格式的指令去引用我们文字标识池中的数据。在上面的例子中我们用一条指令将一个32位的常量值放到了一个寄存器中。为什么我们会这么写是因为ARM每次仅仅能加载8位的值,原因倾听我解释立即数在ARM架构下的处理。
4.7 在ARM中使用立即数的规律
是的,在ARM中不能像X86那样直接将立即数加载到寄存器中。因为你使用的立即数是受限的。这些限制听上去有些无聊。但是听我说,这也是为了告诉你绕过这些限制的技巧(通过LDR)。
我们都知道每条ARM指令的宽度是32位,所有的指令都是可以条件执行的。我们有16中条件可以使用而且每个条件在机器码中的占位都是4位。之后我们需要2位来做为目的寄存器。2位作为第一操作寄存器,1位用作设置状态的标记位,再加上比如操作码(opcode)这些的占位。最后每条指令留给我们存放立即数的空间只有12位宽。也就是4096个不同的值。
这也就意味着ARM在使用MOV指令时所能操作的立即数值范围是有限的。那如果很大的话,只能拆分成多个部分外加移位操作拼接了。
所以这剩下的12位可以再次划分,8位用作加载0-255中的任意值,4位用作对这个值做0~30位的循环右移。这也就意味着这个立即数可以通过这个公式得到:v = n ror 2*r。换句话说,有效的立即数都可以通过循环右移来得到。这里有一个例子
有效值:
#256 // 1 循环右移 24位 --> 256
#384 // 6 循环右移 26位 --> 384
#484 // 121 循环右移 30位 --> 484
#16384 // 1 循环右移 18位 --> 16384
#2030043136 // 121 循环右移 8位 --> 2030043136
#0x06000000 // 6 循环右移 8位 --> 100663296 (十六进制值0x06000000)
Invalid values:
#370 // 185 循环右移 31位 --> 31不在范围内 (0 – 30)
#511 // 1 1111 1111 --> 比特模型不符合
#0x06010000 // 1 1000 0001.. --> 比特模型不符合
看上去这样并不能一次性加载所有的32位值。不过我们可以通过以下的两个选项来解决这个问题:
- 用小部分去组成更大的值。
- 比如对于指令 MOV r0, #511
- 将511分成两部分:MOV r0, #256, and ADD r0, #255
- 用加载指令构造‘
ldr r1,=value’的形式,编译器会帮你转换成MOV的形式,如果失败的话就转换成从数据段中通过PC相对偏移加载。
LDR r1, =511
如果你尝试加载一个非法的值,编译器会报错并且告诉你:Error: invalid constant。如果在遇到这个问题,你现在应该知道该怎么解决了吧。唉还是举个栗子,就比如你想把511加载到R0。
.section .text
.global _start
_start:
mov r0, #511
bkpt
这样做的结果就是编译报错:
azeria@labs:~$ as test.s -o test.o
test.s: Assembler messages:
test.s:5: Error: invalid constant (1ff) after fixup
你需要将511分成多部分,或者直接用LDR指令。
.section .text
.global _start
_start:
mov r0, #256 /* 1 ror 24 = 256, so it's valid */
add r0, #255 /* 255 ror 0 = 255, valid. r0 = 256 + 255 = 511 */
ldr r1, =511 /* load 511 from the literal pool using LDR */
bkpt
如果你想知道你能用的立即数的有效值,你不需要自己计算。我这有个小脚本,看你骨骼惊奇,传给你呦 rotator.py(=https://raw.githubusercontent.com/azeria-labs/rotator/master/rotator.py)。用法如下。
azeria@labs:~$ python rotator.py
Enter the value you want to check: 511
Sorry, 511 cannot be used as an immediate number and has to be split.
azeria@labs:~$ python rotator.py
Enter the value you want to check: 256
The number 256 can be used as a valid immediate number.
1 ror 24 --> 256